【大数据基础】大数据处理架构Hadoop:01 Hadoop概述 本文介绍Hadoop概述。Hadoop是一个开源分布式计算平台,以高可靠性、高效性和可扩展性著称,在各领域尤其是互联网行业应用广泛,且版本不断演进,还有商业发行版。 国内服务器 4个月前480
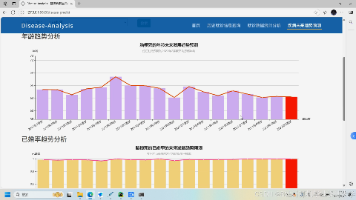
计算机毕业设计Python+大模型深度学习疾病预测系统 疾病大数据 医学大数据分析 大数据毕业设计(源码+LW+PPT+讲解) 本文介绍了一个基于Python和大模型深度学习的多模态疾病预测系统开发项目。项目整合电子病历、医学影像和实验室检查数据,利用医疗领域大模型(如Med-BERT、ViT)提取特征,通过跨模态注意力机制实... 国内服务器 4个月前480
打破AI调用壁垒:Antigravity Tools如何用Rust+Tauri重构你的AI工作流 摘要:AntigravityTools是一个基于Rust和Tauri的开源AI调度系统,旨在解决多AI账号管理和协议转换难题。它支持OpenAI、Claude、Gemini等主流AI协议,通过本地化代... 国内服务器 4个月前480
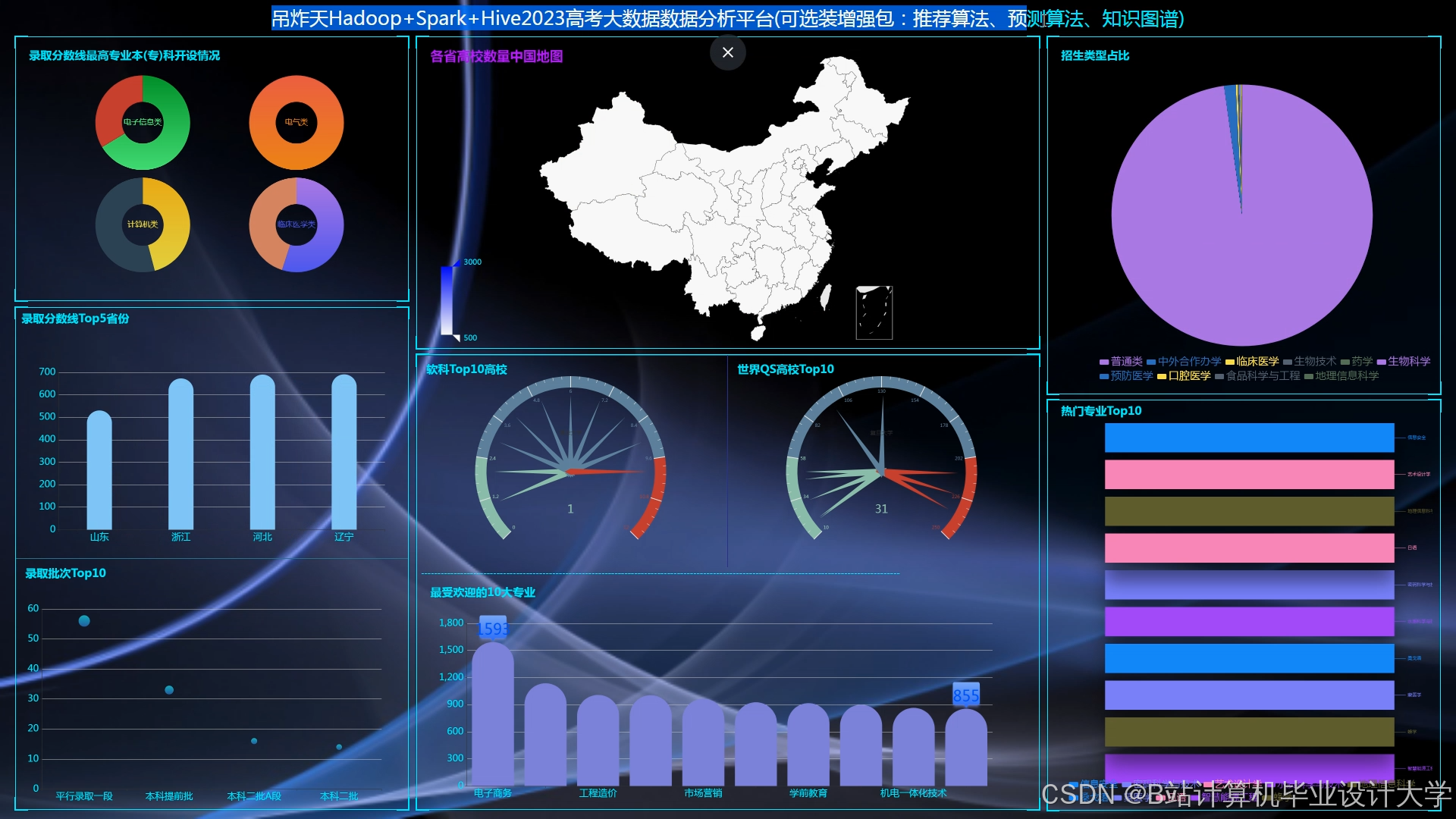
计算机毕业设计Python+PySpark+Hadoop高考推荐系统 高考可视化 大数据毕业设计(源码+LW文档+PPT+详细讲解) 本文介绍了基于Python+PySpark+Hadoop的高考志愿推荐系统设计与实现。该系统整合多源数据(考生成绩、兴趣、高校招生信息等),采用协同过滤和内容过滤混合推荐策略,为考生提供个性化志愿推荐... 国内服务器 4个月前480
第12章: MMU notifier内核演进与未来方向 本文概述了Linux内核中mmu_notifier机制的演进历程。2008年初始版本为KVM虚拟化提供shadow page table同步,采用全局通知模型。2010-2018年通过引入invali... 国内服务器 4个月前480
FlinkSql(详细讲解一) FlinkSQL基础教程摘要:本文介绍了FlinkSQL的核心概念与应用方法。FlinkSQL作为流批统一的处理框架,通过SQL语法简化数据处理流程。主要内容包括:1)核心概念:流批统一处理、表与视图... 国内服务器 5个月前480
CentOS安装Tomcat/Nginx/RabbitMQ/Redis全指南 本文详细介绍了在CentOS系统中安装四种常用服务的完整流程:1) Tomcat 10.1.49安装,包括JDK17配置、专用用户创建和8080端口开放;2) Nginx安装,通过官方YUM仓库配置并... 国内服务器 5个月前480
大模型应用技术之 Spring AI 2.0 变更说明 Spring AI 2.0.0-M1 发布重要里程碑版本,基于Spring Boot 4.0和Spring Framework 7.0构建,需Java 21运行环境。主要更新包括:新增Redis聊天记... 国内服务器 5个月前480
PostgreSQL 数据仓库实战:实时数仓构建 + 离线分析 + 数据湖集成 摘要:PostgreSQL凭借混合负载能力,为中小企业提供轻量级实时数仓解决方案。相比传统Hive+Spark架构,PG数仓具有四大优势:1)架构轻量,部署成本降低80%;2)支持秒级实时同步;3)灵... 国内服务器 5个月前480
电商大促期间Kafka监控实战:可视化工具选型指南 最近参与了一个电商平台的"双11"大促保障项目,负责搭建Kafka消息队列的实时监控系统。它的WebIDE环境预装了常用组件,不用自己搭建监控系统就能做基本观察,适合开发阶段的快速... 国内服务器 5个月前480