Flink原理与实战(java版)#第11章Flink的应用(第三节Table & SQL 连接器之Hive(五)) 介绍Hive作为Table API和SQL的外部连接器使用,并且结合实际应用中会使用kafka作为数据源进行介绍。 国内服务器 1个月前120
Python整合Spark实现数据分析 本文介绍了PySpark 3.5.3在JDK1.8环境下的配置方法。主要内容包括:1) PySpark版本依赖和MySQL驱动的两种配置方式(自动下载或手动放置jar包);2) Flask应用中初始化... 国内服务器 1个月前150
表空间满了却不报错——Oracle的沉默陷阱 表空间满了不报错,是Oracle的一个"特性",不是bug。但在生产系统,特别是政务医疗系统,这种特性会变成致命陷阱。关键点监控表空间使用率,阈值设到85%固定大小数据文件,不用A... 国内服务器 1个月前130
大数据数据标准化与数据治理的关系?一次性讲清楚(附框架图) 标准化是治理的“基础”:没有标准化,治理就没有“统一的语言”,无法落地;治理是标准化的“保障”:没有治理,标准化就没有“执行的动力”,无法持续;两者的目标一致:都是为了“让数据成为可信、可用、可控的资... 国内服务器 1个月前100
Hadoop与视频流分析:内容推荐系统 你是否注意到:当你在视频平台搜索过“猫咪”,半小时后首页就会出现大量猫主子的萌视频;当你看完一部科幻电影,接下来三天推荐列表里全是“太空探险”主题内容?这些“比你更懂你”的推荐,本质是“内容推荐系统... 国内服务器 1个月前130
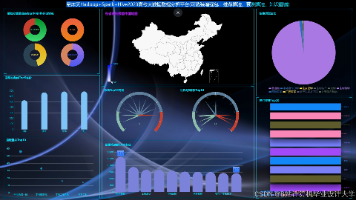
计算机毕业设计hadoop+spark+hive 高考志愿填报推荐推荐系统 高考数据分析可视化大屏 高考爬虫 高考分数线预测 数据仓库 大数据毕业设计 摘要:本项目基于Hadoop+Spark+Hive技术栈开发高考志愿填报推荐系统,整合历年录取数据、院校信息等多源数据,利用Spark进行实时数据处理和机器学习算法实现个性化推荐。系统包含数据存储(H... 国内服务器 1个月前80
深入探讨大数据领域Eureka的服务发现机制 在微服务架构中,一个系统可能由成百上千个独立服务组成(比如电商系统的用户服务、订单服务、库存服务等)。这些服务需要频繁调用彼此,但服务的IP地址和端口会因扩容、故障重启等动态变化。传统的“硬编码地址... 国内服务器 1个月前110
基于Python的电商大数据画像系统的详细项目实例(含完整的程序,数据库和GUI设计,代码详解) 还请多多点一下关注 加油 谢谢 你的鼓励是我前行的动力 谢谢支持 加油 谢谢 本文介绍了一个基于Python的电商大数据画像系统项目,该系统通过整合用户行为数据、交易记录和评价反馈等多源异构数据,构建精准的用户画像模型。项目采用模块化架构设计,包含数据采集、清洗、特征工程、画像... 国内服务器 1个月前150