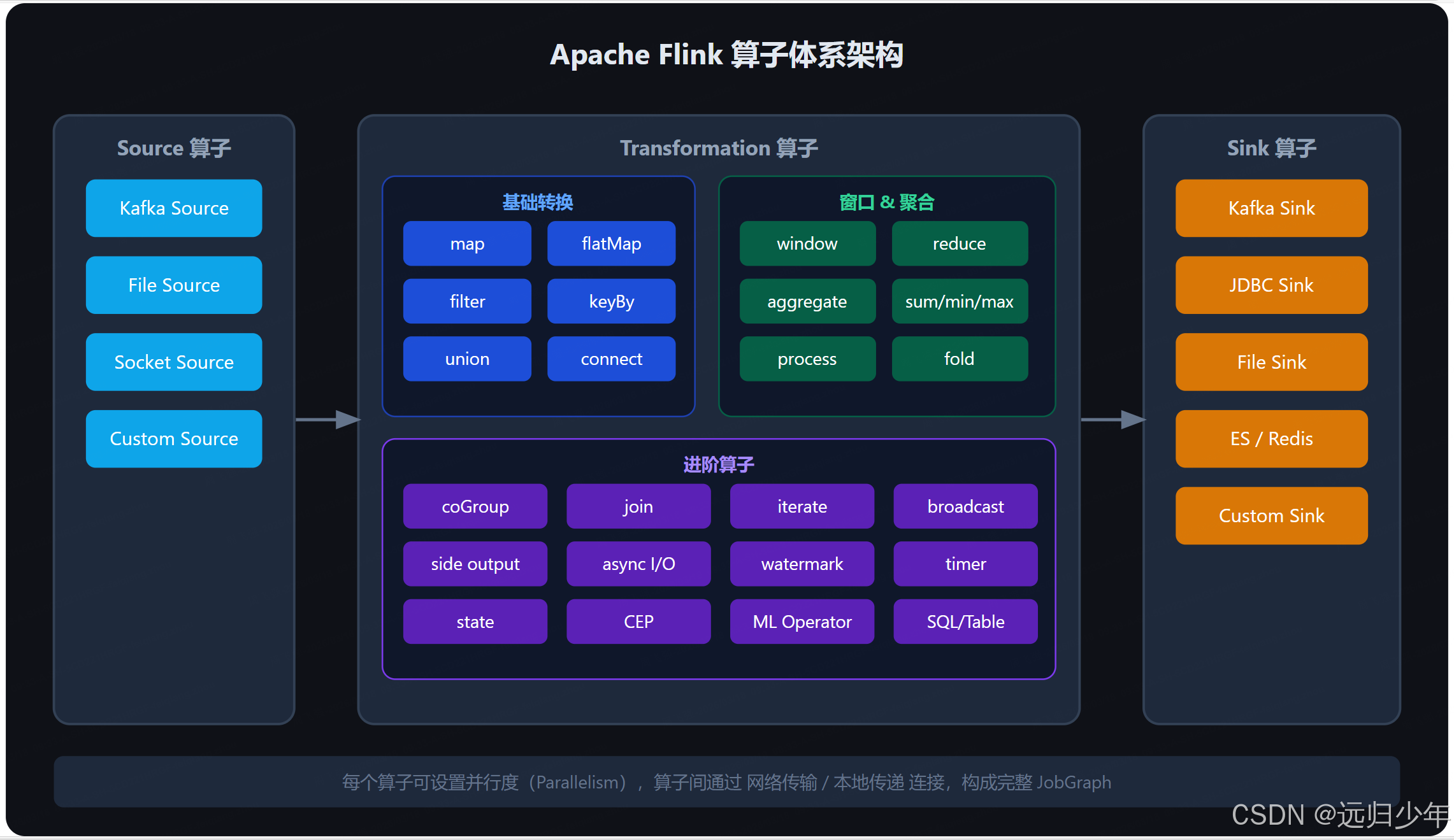
Apache Flink 算子(Operator)深度解析 Flink算子(Operator)是流处理程序的基本计算单元,负责数据转换、聚合等操作,构成有向无环图(DAG)。核心概念包括并行度(Parallelism)和算子链(Operator Chain... 国内服务器 1个月前170
简单课设-基于Spark的流计算实验(一) 摘要:本实验实现了基于HDFS小文件的Spark流处理系统,通过Scala程序生成100个CSV小文件(共10万条气象数据)并上传至HDFS,使用Spark Structured Streaming进... 国内服务器 1个月前140
2026技术趋势全景图:AI、云原生、大数据价值落地|开发者学习路线 2026年技术趋势展望:开发者如何把握AI与云原生机遇 随着技术从"范式重构"进入"价值落地"阶段,2026年开发者将面临全新挑... 国内服务器# Langchain 1个月前360
大数据领域的制药数据研发与创新 制药行业正经历着前所未有的数字化转型。本文旨在系统性地阐述大数据技术如何重塑制药研发流程,提高药物发现效率,降低研发成本。药物靶点发现与验证化合物筛选与优化临床试验设计与分析药物安全监测与上市后研究本... 国内服务器 1个月前180
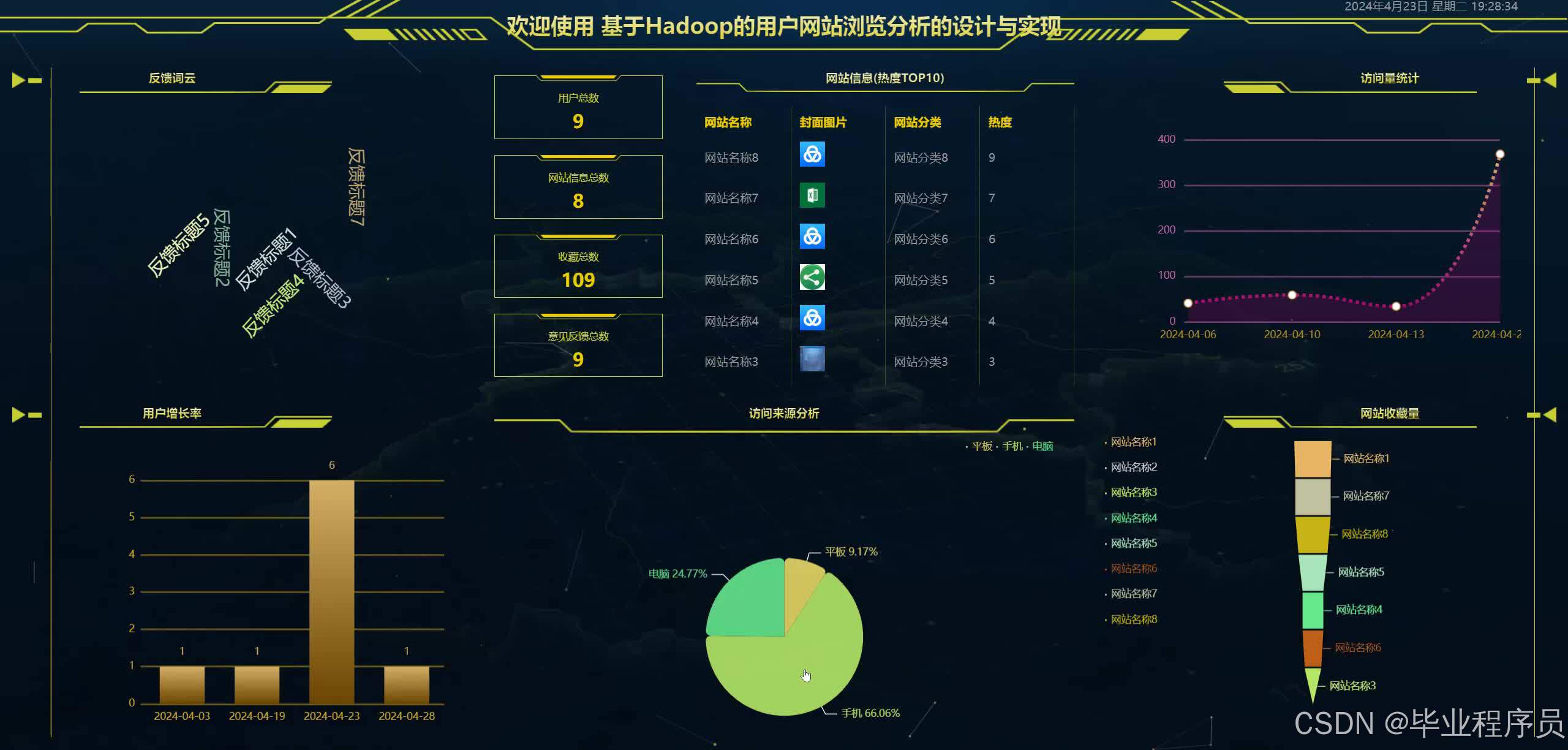
python基于Hadoop的用户网站浏览分析的设计与实现 摘要:本文介绍了一个基于Python和Hadoop技术的用户网站浏览分析系统。该系统利用Python爬虫收集用户浏览数据,通过Hadoop分布式处理框架进行大数据分析,结合MySQL数据库存储结构化数... 国内服务器 1个月前150
头歌 Hive综合应用案例1——用户学历查询 604,f,1996/11/24,本科,人工智能开发工程师,10k,南方,东方,农村。601,f,1993/04/09,本科,Java开发工程师,7k,北方,南方,城市。602,m,1991/05/1... 国内服务器 1个月前180
大数据领域数据仓库在教育行业的应用模式 本文旨在解决教育行业“数据多但用不好”的痛点,系统讲解数据仓库如何将分散在教务系统、考勤机、在线学习平台、家校沟通群中的碎片数据,转化为可指导教学决策的“教育智慧”。覆盖K12、职业教育、高等教育等全... 国内服务器 1个月前160
数据工程与ETL工具:Pandas、Dask、Spark性能对比终极指南 数据工程是现代数据科学和机器学习工作流的核心支柱,而ETL(提取、转换、加载)工具的性能直接影响数据处理效率。在Python数据科学生态中,Pandas、Dask和Apache Spark是三个最流行... 国内服务器 1个月前210
数据仓库性能优化:聚合策略设计与查询加速实战指南 聚合策略在数据仓库中,提前按照业务常用的维度组合进行预计算、汇总、存储,生成聚合表(汇总表),当查询发生时,直接读取聚合结果,而不是重新计算海量明细数据。空间换时间,预计算换性能。聚合策略 = 预计算... 国内服务器 1个月前240