Spark完全分布式集群环境搭建详细教程 本文详细介绍了在Hadoop集群环境下安装和配置Spark的完整流程。主要内容包括:1)准备JDK、Zookeeper和Hadoop集群环境;2)上传并解压Spark安装包;3)配置Spark环境变量... 国内服务器 1个月前190
NVIDIA DGX Spark 开发环境深度配置与优化指南 定期系统维护每月执行一次完整的系统更新监控存储空间使用情况,及时清理临时文件定期检查硬件健康状况开发习惯优化使用tmux或screen管理长时间运行的任务配置自动化测试和代码质量检查建立完善的项目文档... 国内服务器 1个月前160
SPARK AGI:一站式企业级知识库与智能体开发平台 SPARK AGI 智能数据开发平台,通过 链路智能体 自动生成可溯源、可交付的数据资产,打通数据中台落地智能体的“最后一公里” 国内服务器# kimi 1个月前170
cv_resnet50_face-reconstruction开源可部署实践:某省大数据局人脸图像治理平台集成案例 本文介绍了如何在星图GPU平台自动化部署cv_resnet50_face-reconstruction镜像,实现高效人脸图像重建。该方案特别适用于老旧档案数字化和监控视频人脸增强等场景,能显著提升模糊... 国内服务器 1个月前140
Spring In Action 5 Samples消息队列集成:Kafka与RabbitMQ实现 Spring In Action 5 Samples项目提供了丰富的Spring框架实践案例,其中消息队列集成部分展示了如何在Spring应用中优雅地实现Kafka与RabbitMQ消息通信。本文将带... 国内服务器 1个月前130
大数据领域数据仓库的数据分析方法 随着企业数据量以年均40%的速度爆炸式增长(Gartner, 2023),传统数据库已难以支撑复杂的数据分析需求。数据仓库作为面向主题、集成、稳定且随时间变化的数据集合,成为企业级数据分析的核心基础设... 国内服务器 1个月前200
【大数据毕设选题】基于Spark+Django的胆结石消化系统疾病数据分析系统源码 毕业设计 选题推荐 毕设选题 数据分析 机器学习 数据挖掘 为探究胆结石风险因素,本系统构建了基于Spark+Django的数据分析平台。利用Hadoop存储海量医疗数据,通过Spark SQL及Pandas进行多维度分析,涵盖人口统计学、体成分、血脂等指标... 国内服务器 1个月前160
计算机毕业设计Hadoop+Spark+Hive酒店推荐系统 酒店可视化 酒店爬虫 大数据毕业设计(源码+文档+PPT+讲解) 本文提出基于Hadoop+Spark+Hive的酒店推荐系统,通过分布式架构整合用户行为、酒店属性和情境数据,构建混合推荐模型。系统采用五层架构实现数据采集、存储、处理和推荐闭环,创新性地提出动态权重... 国内服务器 1个月前170
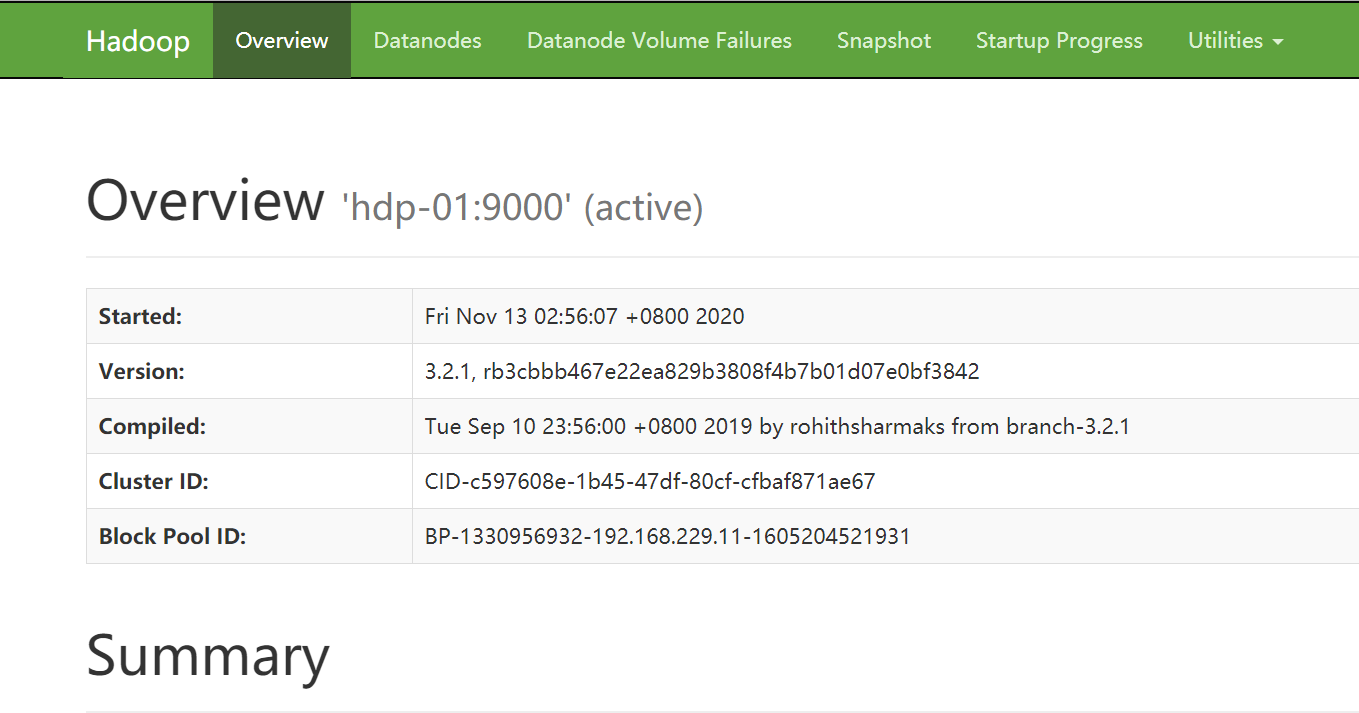
Hadoop:HDFS 集群环境搭建 HDFS 集群由一个主/从架构组成,单个运行 NameNode 进程的服务器为主节点服务器,多个运行 DataNode 进程的服务器为从节点服务器。 国内服务器 1个月前160
DGX Spark (Blackwell) 部署 Qwen3.6 35B FP8 踩坑实录:从无限崩溃到成功跑通 本文记录了在全新 NVIDIA DGX Spark G10(Blackwell ARM64架构)服务器上,使用 vLLM 部署 Qwen3.6-35B-A3B-FP8 模型的硬核踩坑实录。针对新硬件架... 国内服务器 1个月前300