kafka入门及原理分析 Kafka是一个分布式流处理平台,于处理高吞吐量的实时数据流。核心功能包括发布-订阅消息系统、持久化存储和高可用性。同步因通讯/业务链路耗时过长,引发性能和稳定问题。通过kafka(分布式、多分区、多... 国内服务器 4个月前460
Apache Flink 在 Kubernetes 上的高效部署与优化实践 本文档提供Kubernetes环境下部署Apache Flink作业的系统化实践方案。在镜像构建方面,建议采用多阶段构建合并RUN指令,分离基础镜像与作业镜像;资源调度上,通过节点标签划分固定与弹性节... 国内服务器 4个月前460
lasticsearch 9.3.0 日志分类功能完整指南 本文介绍了日志分类功能及其部署配置要求。日志分类通过自动分组非结构化日志消息,将海量日志归纳为少数类别,显著提升排查效率。部署方式分为Serverless(自动托管)和Stack(需手动配置ML节点... 国内服务器 4个月前460
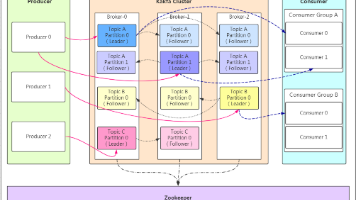
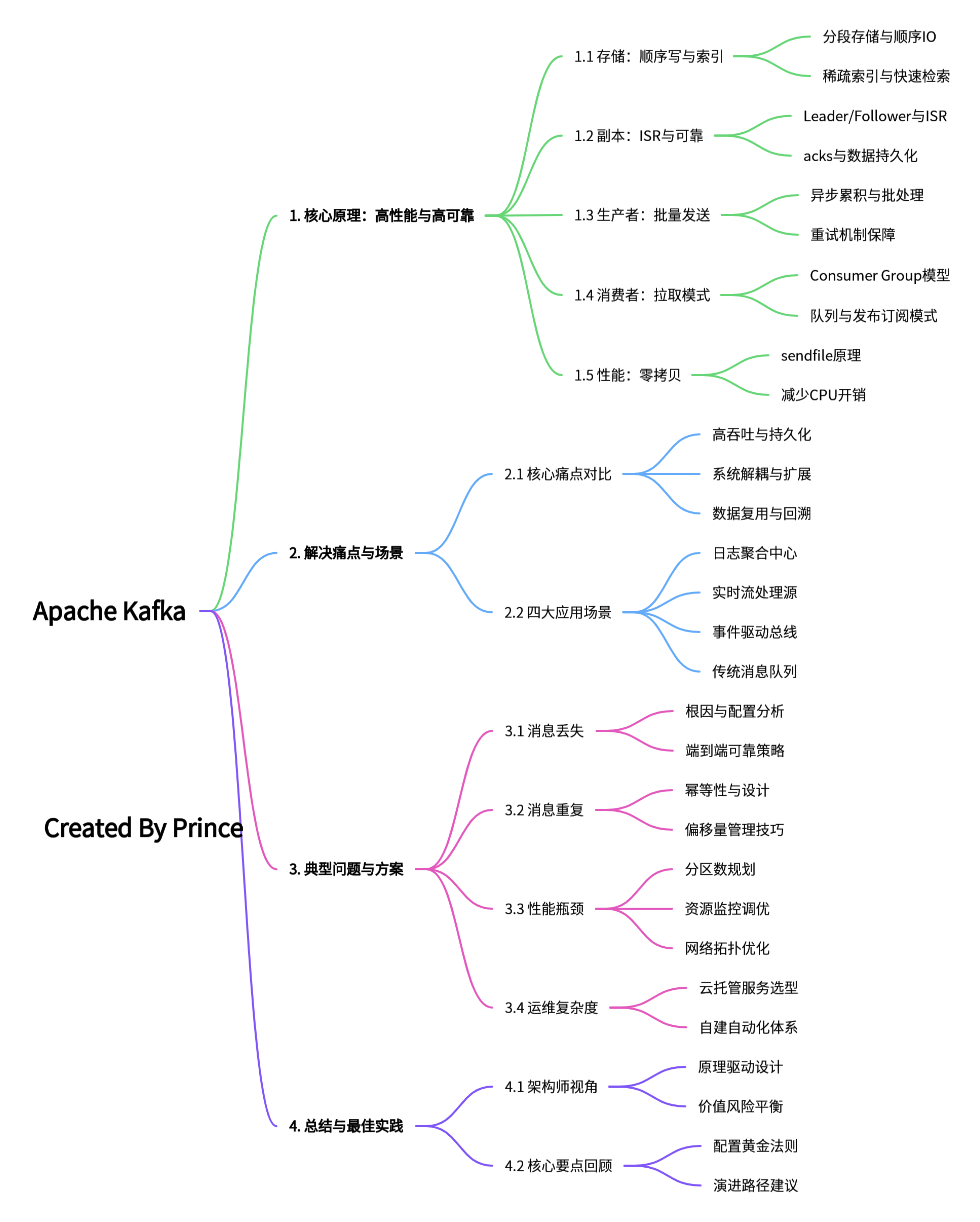
技术架构系列 – 详解Kafka 查找时,先通过二分法确定消息所在的Segment,再在内存中的索引文件里进行二分查找,找到最接近的索引条目,最后在。在传统的数据从磁盘发送到网络的过程中,数据需要在操作系统内核空间和用户空间之间多次拷... 国内服务器 4个月前460
浅谈大数据领域数据标注的流程优化 在AI主导的大数据时代,数据标注是所有监督学习模型的“燃料”——没有高质量的标注数据,再先进的模型(如GPT-4、ResNet)也无法发挥作用。效率低:纯人工标注10万条文本数据需要数周甚至数月,无法... 国内服务器 4个月前460
实时知识增强大模型:基于Flink的流式向量索引与动态RAG系统 本文提出了一种面向大模型应用的实时数据流处理架构,通过FlinkCDC+Milvus增量索引+动态Prompt注入技术,实现知识库分钟级更新与毫秒级查询。该架构创新性地采用时间感知向量编码与热点数据预... 国内服务器 4个月前460
01 | 数据仓库主题域如何划分 主题域是面向业务分析、围绕某一核心业务过程或对象组织起来的数据集合,代表企业中一个相对独立、稳定的业务领域。主题域划分的本质,是将混沌的原始数据,转化为结构化的业务语言。✅好的主题域划分应做到业务人员... 国内服务器 4个月前460
计算机毕业设计Hadoop+Spark慕课课程推荐系统 知识图谱 大数据毕业设计(源码 +LW文档+PPT+讲解) 摘要:本项目基于Hadoop和Spark技术开发慕课课程推荐系统,实现个性化课程推荐功能。系统包含数据采集、存储预处理、推荐引擎、评估优化和用户界面五大模块,采用协同过滤与内容过滤相结合的混合推荐算法... 国内服务器 4个月前460
Kafka核心优化机制:Batch+Request底层原理与缓冲池设计深度解析 Kafka通过Batch+Request机制实现高吞吐传输,核心原理是分层批量处理:消息先按分区封装为Batch,再按Broker聚合为Request,减少网络IO次数。客户端采用CopyOnWrit... 国内服务器 4个月前460
【大数据毕设选题推荐】基于Hadoop+Django健康保险数据可视化系统源码 毕业设计 选题推荐 毕设选题 数据分析 本项目设计并实现了一个基于Hadoop与Spark的健康保险数据可视化分析系统。系统利用HDFS存储海量保险数据,通过Spark进行高效的分布式计算与数据分析,包括医疗费用关联、投保人画像及保费特征分... 国内服务器 4个月前460