Java 大视界 — Java 大数据在智能教育在线考试系统中的考试结果分析与教学反馈优化中的应用(420) 本文聚焦智能教育在线考试系统 “分析浅、反馈慢、个性化弱” 痛点,结合 Java 大数据技术(Spark/Flink/Elasticsearch),拆解多维考试结果分析、实时个性化反馈两大核心场景,附... 国内服务器 2个月前270
Hive SQL中COALESCE 函数和NVL()函数、IFNULL函数区别 Hive 中的NVL()是双参数函数,用于将 NULL 值替换为指定的非 NULL 值,语法和行为与 Oracle 的NVL()完全兼容。语法作用:如果expression为 NULL,则返回repl... 国内服务器 2个月前150
ComfyUI与Zookeeper协调服务集成:分布式环境同步 本文探讨如何通过Apache Zookeeper实现ComfyUI在分布式环境中的服务发现、配置同步与任务队列管理,解决多节点协同中的状态一致性与容错问题,提升AI生成工作流的可靠性与可扩展性。 国内服务器 2个月前150
Kafka – 跨集群数据同步:MirrorMaker2使用教程 本文介绍了Kafka MirrorMaker 2(MM2)的核心概念和使用方法。MM2是基于Kafka Connect框架构建的跨集群数据同步工具,相比旧版MirrorMaker具有更强的功能和可扩展... 国内服务器 2个月前180
【大数据存储与管理】分布式数据库HBase:05 HBase运行机制 本文讲解HBase运行机制。HBase架构清晰,Region服务器是关键。Store含内存缓存与磁盘文件,读写操作依赖二者。HLog保障系统容错,故障时借助其与Zookeeper实现数据恢复。 国内服务器 2个月前180
HBase与Presto集成:交互式查询解决方案 业务系统产生的海量数据(如用户行为日志、IoT设备数据)需要用HBase高效存储(支持百万级QPS写入);但业务人员需要用SQL快速查询这些数据(如“统计近7天活跃用户的地域分布”),HBase原生的... 国内服务器 2个月前180
基于大数据的国产跑鞋推荐系统的设计与实现 本文提出了一种基于大数据爬虫和Hadoop的国产跑鞋智能推荐系统。该系统针对当前国产跑鞋市场快速增长但用户匹配效率低的问题,采用Java+Spring Boot技术架构,结合MySQL数据库,实现了多... 国内服务器 2个月前160
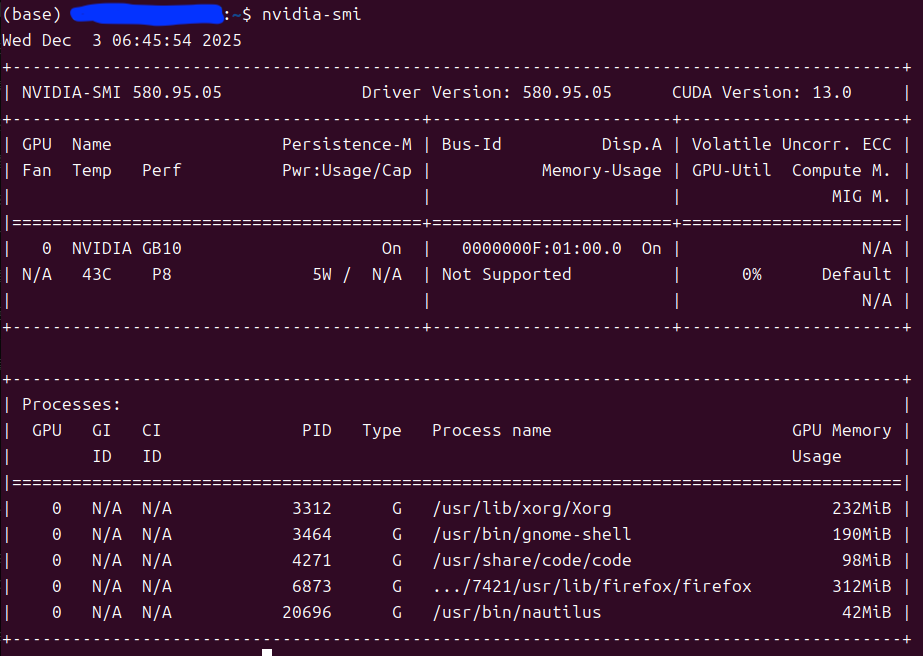
NVIDIA DGX Spark(Ubuntu24.04)安装isaacsim和isaaclab+ros2 isaacsim和isaaclab有三种安装方法:源码编译,二进制编译,pip安装。源码编译会有非常非常非常多的bug,而且速度很慢,不建议尝试。pip安装速度最快,可参照我的这篇文章pip在NVID... 国内服务器 2个月前200
10分钟快速验证:用Kafka构建实时日志收集原型 这种快速验证方法优点明显:环境搭建快:从下载到运行不到5分钟代码可复用:核心逻辑可直接移植到正式项目成本低:单机即可验证基础场景在InsCode(快马)平台实践时更便捷,不用配环境就能直接运行完整de... 国内服务器 2个月前150