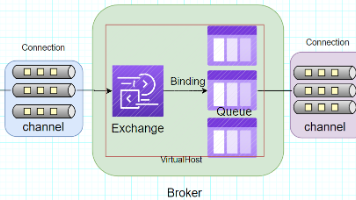
RabbitMQ 全链路解析:底层原理 + 高并发调优 + 百万级落地 《RabbitMQ实战指南:从基础到高可用架构》 本文是一份RabbitMQ生产级实践指南,涵盖消息队列核心概念到高级特性。文章首先通过餐厅点餐案例生动解释消息队列的异步解耦价值,随后详细解析Rabb... 国内服务器 2个月前210
Docker核心要点和指令速通 本文梳理了 Docker 的核心知识点与常用命令,涵盖镜像管理、容器操作、数据卷、网络配置、Dockerfile 编写及 Compose 编排。适合快速查阅和日常备忘,希望能帮你提升容器化开发效率。 国内服务器 2个月前240
计算机毕业设计Python+PySpark+Hadoop视频推荐系统 视频弹幕情感分析 大数据毕业设计(源码+文档+PPT+ 讲解) 本文介绍了基于Python+PySpark+Hadoop的视频推荐系统开发任务书模板。系统利用Hadoop分布式存储和PySpark计算框架,实现离线与实时视频推荐功能,包括协同过滤、内容推荐等算法... 国内服务器 2个月前220
Java 大视界 — Java 大数据在智能医疗电子病历数据分析与临床科研中的应用(314) 本文系统阐述 Java 大数据技术在电子病历分析与临床科研中的应用,涵盖数据治理架构、NLP 处理、科研分析平台及安全方案,结合瑞金医院、协和医院等真实案例,提供从数据采集到价值挖掘的全流程技术实现。 国内服务器 2个月前180
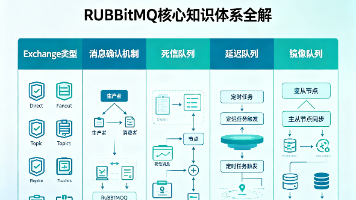
【RabbitMQ】RabbitMQ核心知识体系全解(5大核心模块:Exchange类型、消息确认机制、死信队列、延迟队列、镜像队列) 本文基于AMQP协议与RabbitMQ原生能力,全方位、结构化拆解 “ Exchange类型、消息确认机制、死信队列、延迟队列、镜像队列 ” 五大核心模块,同时梳理模块间的内在关联,形成完整的Rabb... 国内服务器 2个月前170
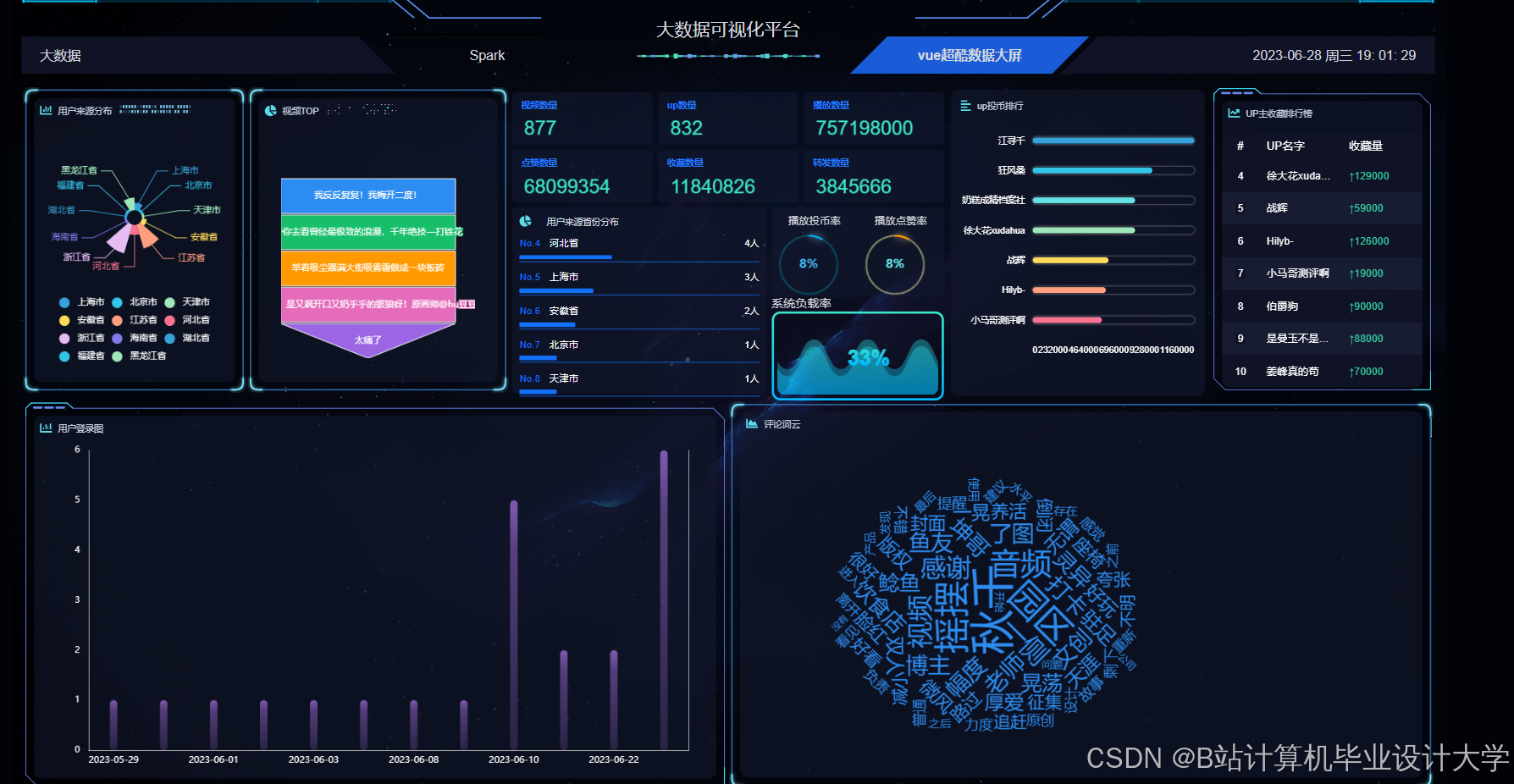
hadoop+Spark+springboot基于大数据的高校网络舆情监控引导系统(源码+文档+调试+可视化大屏) 摘要:本文介绍了一个基于SpringBoot和大数据技术的高校网络舆情监控引导系统。该系统采用Java语言开发,整合Hadoop、Spark等大数据处理技术,结合Vue.js前端框架,实现对校园网络舆... 国内服务器 2个月前210
大数据领域数据可视化:构建清晰的数据图景 在大数据时代,我们每天都会接触到海量的数据。这些数据就像一座巨大的宝藏,但如果不进行有效的处理和展示,我们很难从中发现有价值的信息。数据可视化就是打开这座宝藏的钥匙,它可以将复杂的数据转化为直观的图形... 国内服务器 2个月前260
ZipArchive终极指南:iOS/macOS文件压缩解压的完整解决方案 ZipArchive是一个专为Apple生态系统设计的强大文件压缩解压库,支持iOS、macOS、tvOS、watchOS和visionOS平台。这个开源工具让开发者在应用中轻松实现文件压缩与解压功能... 国内服务器 2个月前210
PySpark vs传统方法:大数据处理效率提升10倍的秘密 尝试了传统Pandas方法和PySpark两种方案后,效率差距让我大吃一惊。我生成了包含1000万条记录的模拟电商订单数据,每条记录包含订单ID、用户ID、商品ID、购买数量、金额和时间戳等字段。为了... 国内服务器# kimi 2个月前210
互联网大厂Java面试实录:从Spring Boot到Kafka的深度之旅 作为现代Java开发的事实标准,大大简化了项目搭建和配置管理Redis作为高性能缓存,是应对高并发的利器,但需要深入理解其各种边界情况Kafka作为分布式消息系统,实现了系统的异步解耦和流量削峰,是大... 国内服务器 2个月前160