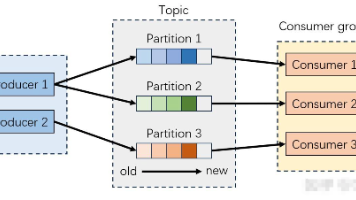
Kafka从入门到精通:全流程技术指南 本专栏针对Kafka 0-3年开发者,系统讲解从基础到高级的全流程应用。包含5大模块:基础入门(环境搭建、消息收发)、消息存储与分区策略(Log Segment、副本机制)、高级优化(事务、性能调优... 国内服务器 4个月前440
RabbitMQ – 公平分发与轮询分发的区别与配置 RabbitMQ消息分发策略对比与实践 本文深入探讨了RabbitMQ中两种核心消息分发机制:轮询分发和公平分发。轮询分发是RabbitMQ的默认策略,它按照消费者连接的顺序循环分配消息,不考虑处理能... 国内服务器 4个月前440
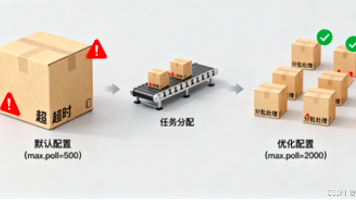
【分布式利器:Kafka】3、Kafka重平衡避坑指南:5个配置解决90%问题 Kafka重平衡(Rebalance)是消费者组的分区重新分配机制,看似智能却常引发消费暂停、消息重复等问题。本文提供5个核心配置解决方案: 合理设置心跳超时参数(session.timeout.ms... 国内服务器 4个月前440
Kafka常见问题解答 Broker是Kafka集群中的一个个独立的服务器节点(物理机或虚拟机)。您可以将其理解为一个Kafka服务实例。单个Broker可以轻松处理每天数TB的消息流量。多个Broker相互协作,共同组成了... 国内服务器 4个月前440
RabbitMQ如何成为分布式系统的“神经中枢“?——从安装部署到C++调用实战的完整流程,带你体验它的奥妙所在! 本文档围绕RabbitMQ展开,涵盖其概念、安装、AMQP - CPP库使用及客户端API封装。阐述消息队列原理、特性,详述Linux下安装步骤、库安装,展示简单使用案例与API封装思路。 国内服务器 4个月前440
【Prometheus】RabbitMQ安装部署,如何通过prometheus监控RabbitMQ RabbitMQ是一个开源的消息代理和队列服务器,它使用Erlang语言编写并运行在多种操作系统上,如Linux、Windows等。RabbitMQ可以接收、存储和转发消息(也称为“事件”)到连接的客... 国内服务器 4个月前440
Python毕业设计选题推荐:基于大数据的美食数据分析与可视化系统实战 本文介绍了一个基于Python技术栈的大众点评美食数据分析与可视化系统。系统采用Scrapy框架爬取店铺信息,利用Spark进行数据清洗和聚合分析,构建了区域特征、消费者偏好、质量评价和商业价值四大分... 国内服务器 4个月前440
从命令行迷宫到可视化殿堂:Kafka管理的革命性蜕变 深夜两点,运维工程师小李盯着终端窗口,手指在键盘上飞快敲击。这是他今晚第7次执行`kafka-consumer-groups.sh`命令,试图找出导致消息积压的罪魁祸首。复杂的参数、冗长的输出、难以关... 国内服务器 5个月前440
深度解析Kafka重平衡,触发机制、执行流程与副本的核心关联 Kafka中重平衡与副本机制深度解析 摘要:本文深入剖析Kafka中重平衡与副本两大核心机制的关联关系。重平衡作为消费端的负载均衡机制,与Broker端的副本调度操作虽维度不同,却通过Leader副本... 国内服务器 5个月前440