PostgreSQL:详解 PostgreSQL 与Hadoop与Spark的集成 本文介绍了PostgreSQL与Hadoop生态及Spark的深度集成方案。PostgreSQL作为OLTP数据库,通过与Hadoop(HDFS/Hive)和Spark的协同,可构建完整的混合数据处理... 国内服务器 2个月前200
MapReduce与Kafka实时数据处理 本文从“批处理的局限性”入手,介绍了Kafka的实时性优势,然后通过架构设计和实战,实现了Kafka+MapReduce的实时数据处理。核心要点回顾MapReduce:擅长大规模批处理,但延迟高;Ka... 国内服务器 2个月前230
线性回归基于大数据Python的智能房价分析与预测系统设计开题_9166ra6h LSTM算法:LSTM(长短期记忆网络)是一种深度学习算法,特别适合处理序列数据。在酒店评论情感分析中,LSTM能够捕捉文本中的长期依赖关系,精准识别情感倾向,有效提升情感分析的准确性和鲁棒性。Dja... 国内服务器 2个月前210
【JAVA探索之路】简单聊聊Kafka 它提供了高级的DSL和低级的Processor API,支持窗口、连接、聚合等复杂操作,并与Kafka的状态存储紧密集成,实现有状态的、容错的流处理。从各种源头(应用日志、数据库变更、传感器)收集数据... 国内服务器 2个月前220
RabbitMQ在大数据用户行为分析中的应用 用户行为数据是典型的流数据高吞吐量:海量用户产生的行为数据,每秒可达百万级;低延迟要求:实时推荐、 fraud detection等场景需要秒级甚至毫秒级处理;异构性:数据格式包括JSON、Proto... 国内服务器 2个月前190
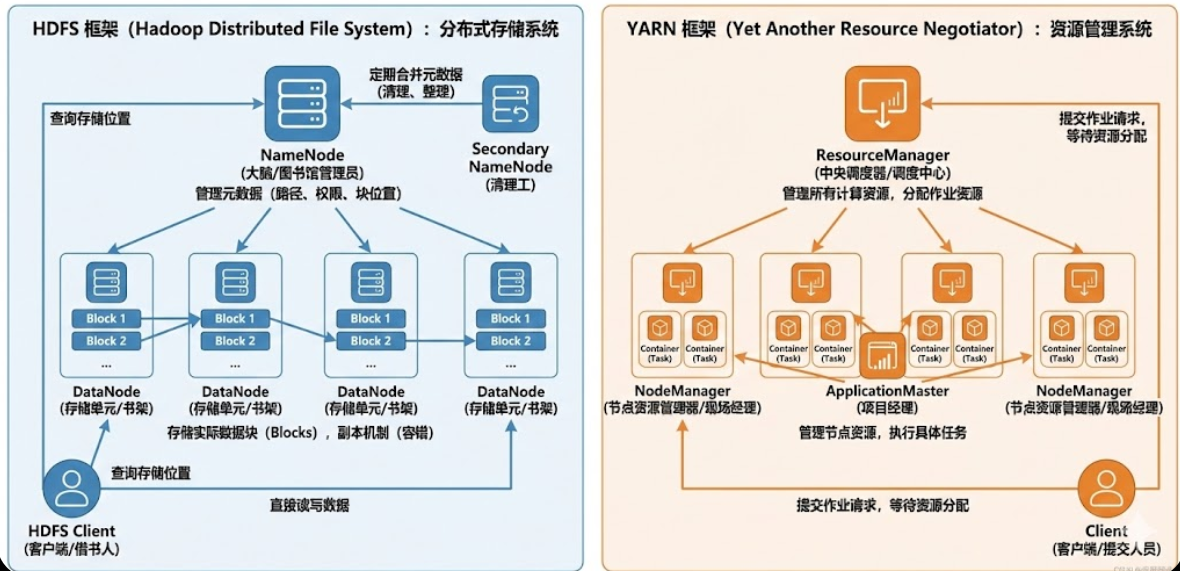
hadoop中HDFS框架、YARN框架各组件职责与对比 简而言之,HDFS 和 YARN 各自担任不同的角色。HDFS 作为存储系统,负责数据的分布式存储和管理,确保数据的高可用性;而 YARN 作为资源管理系统,负责调度和管理集群资源,确保作业能够高效执... 国内服务器 2个月前230
FlutterHive:基于 Flutter × Harmony6.0 的分类与标签构建实践 本文介绍了基于Flutter和Harmony6.0的分类与标签构建实践。通过Flutter的跨平台特性,开发者可以高效实现适配多端设备的分类标签功能。文章详细解析了核心代码实现,包括使用Wrap布局实... 国内服务器 2个月前240
Ubuntu20.04搭建Hadoop大数据生态——从零开始:Ubuntu 20.04 搭建Hadoop+Hive+HBase+Spark大数据平台全攻略 本教程详细介绍了在Ubuntu 20.04系统上搭建Apache Hadoop大数据生态平台的完整流程。内容包括HDFS、YARN、Hive、HBase和Spark的安装配置,重点讲解了版本兼容性选择... 国内服务器 2个月前240
大数据领域 HDFS 数据压缩算法比较与选择 在大数据时代,数据量呈现爆炸式增长,HDFS 作为大数据存储的重要基础,面临着巨大的存储压力。数据压缩是缓解存储压力、降低传输成本的有效手段。本文的目的就是深入比较 HDFS 中常用的数据压缩算法,明... 国内服务器 2个月前240
Kafka Partition 深度解析:数据分片的艺术与性能之舞 Partition(分区)是 Kafka 中消息的物理存储单元。每个 Topic 可以被划分为多个 Partition,每个 Partition 是一个有序的、不可变的消息序列,并以日志文件的形式存储... 国内服务器 2个月前300