前端工程化避坑总结:2026 上半年最值得关注的构建工具与策略演变 构建工具:Vite(中小型 SPA)、Rspack(webpack 迁移)、Turbopack(Next.js 专属)各有最优区间样式方案:Tailwind CSS 成为事实标准,CSS-in-JS ... 国内服务器 6天前60
ZooKeeper 访问控制实战:如何实现对单个 IP 的访问拒绝? ZooKeeper 本身不支持直接拒绝 IP,需要借助外部工具或组合方案防火墙方案最直接:通过 iptables/ufw 在操作系统层拦截绑定监听 IP 最根本:修改让服务只监听内网IP-ACL 方案... 国内服务器 6天前70
Eureka 对大数据领域微服务架构的重要性 本文旨在全面分析Eureka服务发现机制在大数据微服务架构中的应用价值和技术实现。我们将探讨Eureka如何解决分布式系统中的服务定位问题,特别是在大数据场景下处理高并发、高可用的特殊需求。文章首先介... 国内服务器 6天前40
AI工具链7月选型总结:LangChain、向量数据库与LLMOps工具生态 核心技术提炼:框架选型原则:简单LLM调用→原生SDK,复杂Agent→LangChain+LangGraph,文档密集型→LlamaIndex。概括:复杂度决定框架层次,能用原生绝不用框架。向量数据... 国内服务器 6天前90
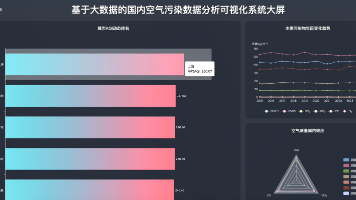
【数据分析】基于大数据的国内空气污染数据分析可视化系统 | 大数据实战项目 毕业设计选题推荐 hadoop SPark Python 【摘要】本文介绍了一款基于大数据的国内空气污染数据分析可视化系统。该系统采用Hadoop集群存储海量数据,利用Spark框架进行高效并行处理,支持Python/Java双后端开发(Django/Spr... 国内服务器 6天前50
Hive数据一致性问题:分桶表_分区表数据倾斜与一致性保障技巧 深夜排查数据倾斜的崩溃、统计报表重复计算的焦虑、ETL重试导致的数据遗漏——这些是每一个Hive用户都可能遇到的“痛点”。分桶表与分区表作为Hive优化查询的核心工具,却常常因数据倾斜(某分区/桶数据... 国内服务器 6天前70
SpringBoot 集成 RabbitMQ 实战(消息队列):实现异步通信与系统解耦 本文介绍了RabbitMQ在分布式系统中的核心应用,重点讲解如何通过SpringBoot集成实现消息队列的实战开发。文章首先分析了同步通信的痛点,指出RabbitMQ在系统解耦、异步通信、流量削峰等方... 国内服务器 6天前70
Python 数据分析实战:处理千万级用户行为数据 用户行为日志对互联网公司来说既是宝贵资源,也是处理难题。一条日志看似简单——用户ID、事件名、时间戳、几个参数——但当日活千万的产品每天产生5亿条日志时,这些看似简单的字段会迅速变成处理难题。存储格式... 国内服务器 6天前60
Symfony 8 + RabbitMQ 实战:构建可靠异步通信的7个关键步骤 掌握Symfony 8 的微服务通信难题?本文详解基于Symfony 8 + RabbitMQ构建可靠异步通信的7个关键步骤,涵盖消息队列配置、服务解耦与错误处理机制,提升系统稳定性与扩展性,值得收藏... 国内服务器 6天前80