Eureka在大数据领域的创新应用探索 在大数据时代,数据量呈爆炸式增长,大数据系统面临着高并发、高可用、可扩展性等诸多挑战。Eureka作为Netflix开源的服务发现组件,在分布式系统中发挥着重要作用。本研究的目的在于探索Eureka在... 国内服务器 2个月前230
RocketMQ-Flink实时流处理框架深度解析与实战指南 RocketMQ-Flink作为Apache Flink与RocketMQ深度集成的实时数据处理框架,为企业级流式计算应用提供了强大的技术支撑。本文将全面剖析该框架的核心特性、架构设计及实际应用场景... 国内服务器 2个月前260
Flink 安装部署 本文介绍了Apache Flink的安装部署指南,包括单机、分布式集群和YARN/Docker部署方式。主要内容涵盖:环境准备(JDK、Hadoop)、下载安装包、配置环境变量、Flink集群配置、启... 国内服务器 2个月前310
Scikit-learn ROC曲线超直观 Scikit-learn的ROC曲线实现,远不止是API的简化,而是机器学习工具链设计的范式转变。它将抽象的统计概念转化为可操作的视觉语言,让开发者从“计算者”变为“决策者”。当ROC曲线如呼吸般自然... 国内服务器 2个月前240
2026年时序数据库选型指南:Apache IoTDB从大数据与物联网视角深度剖析 时序数据库选型指南:关键维度与主流产品分析 2026年,时序数据成为企业数字化转型的核心资产,全球时序数据库(TSDB)市场预计2031年达7.76亿美元。面对41款产品(中国占17款),科学选型需聚... 国内服务器 2个月前250
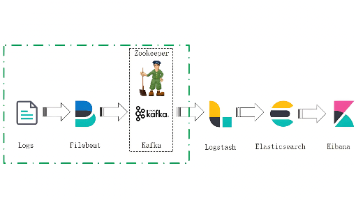
集成Kafka 、 ELK实现高吞吐日志采集是Filebeat 还是Fluentbit? 摘要:本文对比了两种高吞吐日志采集方案:Filebeat+Kafka+ELK和Fluentbit+Kafka+ELK。Filebeat专为结构化日志文件设计,配置简单、资源占用低;Fluentbit则... 国内服务器 2个月前300
车流预测的实时性革命:Kafka Streams如何将延迟压缩至50ms? 本文提出基于Kafka Streams的毫秒级车流预测实时优化方案。针对传统系统因200ms延迟导致预测准确率降至62.3%、拥堵率飙升47%的问题,通过5层架构优化:1)采用1秒滑动窗口的数据采集... 国内服务器 2个月前260
Spring Boot 整合 Kafka:生产环境标准配置与最佳实践 本文介绍了在SpringBoot 3.x项目中集成Apache Kafka的完整方案。主要内容包括:1) 环境准备要求Java 17+和Kafka 3.6.x;2) 项目搭建需添加spring-kaf... 国内服务器 2个月前220
RabbitMQ – 分布式追踪:集成 SkyWalking 实现消息链路追踪 Bean@Bean@Bean统一 Agent 版本:确保所有服务使用相同版本的 SkyWalking Agent。合理命名服务应具有业务含义(如生产环境使用持久化存储:避免 H2 导致数据丢失。监控 ... 国内服务器 2个月前230
数据仓库核心概念:事实表和维度表详解与实战应用 事实表是数据仓库中存储业务度量值、量化指标、可统计数据的核心表,是数仓的主体数据。事实表 = 业务发生的客观事实 + 可统计的数字指标,记录的是企业的业务行为结果。数字、指标、度量、行为记录维度表是数... 国内服务器 2个月前250