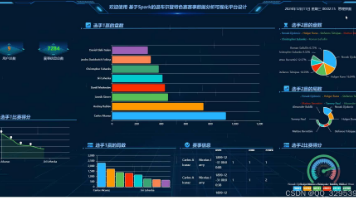
基于Spark的温布尔登特色赛赛事数据分析可视化平台设计与实现(源代码+文档+PPT+调试+讲解) 在网球赛事数据爆发式增长、温网特色赛(草地赛制、历史战绩、球员技战术)分析维度单一的背景下,基于 Spark 的温网赛事数据分析可视化平台,能解决 “海量数据处理效率低、技战术规律挖掘浅、分析结果不直... 国内服务器 4个月前420
【Kafka基础篇】Kafka高可用核心:ISR机制与ACK策略详解,吃透可靠性与吞吐量权衡 本文深入解析Kafka高可用机制中的ISR(同步副本集合)与Producer ACK策略。首先厘清核心概念:AR(所有副本)、ISR(同步副本)和OSR(非同步副本)的关系与判定标准。随后详细拆解IS... 国内服务器 4个月前420
python从入门到精通:pyspark实战分析 spark:Apache Spark是用于大规模数据(large-scala data)处理的统一(unified)分析引擎。简单来说,Spark是一款分布式的计算框架,用于调度成本上千的服务器集群... 国内服务器 4个月前420
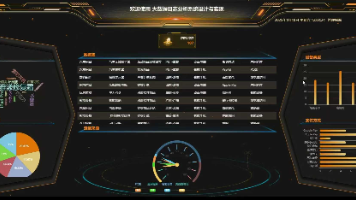
大数据领域数据架构的农业数据挖掘与应用 农业作为人类最古老的生产活动之一,正经历着由传统向数字化、智能化转型的关键时期。本文旨在探讨如何利用大数据技术解决农业生产中的关键问题,包括作物产量预测、病虫害预警、精准灌溉和资源优化等。研究范围涵盖... 国内服务器 4个月前420
Java 大视界 — Java 大数据在智能医疗电子健康档案数据挖掘与健康服务创新中的应用(350) 本文结合 15 个医疗案例,详解 Java 大数据在电子健康档案(EHR)中的应用。多源 EHR 整合准确率 99.2%,跨院调阅从 3 分钟→15 秒,慢性病预测准确率 89%,附隐私保护代码与服务... 国内服务器 4个月前420
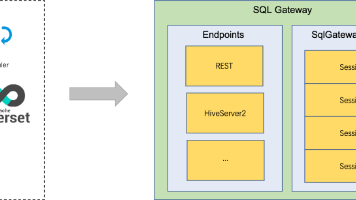
Flink SQL Gateway 把 Flink SQL 变成“多客户端并发可用”的统一服务入口 本文介绍了 Apache Flink SQL Gateway 的核心功能与应用场景。SQL Gateway 作为 Flink 的 SQL 服务化入口,支持多用户并发访问、标准协议接入和统一资源管理。文... 国内服务器 4个月前420
大数据项目(一):Hadoop 云网盘管理系统开发实践 在日常工作和学习中,我们经常需要管理大量的文档资料。传统的本地存储方式存在诸多不便:文件分散难以统一管理、跨设备访问困难、数据安全性无法保障等。因此,我开发了 **NetWorkBase** —— 一... 国内服务器 4个月前420
大数据择优出国留学信息推荐系统开题报告 本文旨在开发一套基于大数据技术的择优出国留学信息推荐系统,以解决当前留学信息碎片化、推荐精准度低等问题。系统将整合全球院校、专业、费用等多维度数据,运用机器学习算法构建个性化推荐模型,实现院校与学生的... 国内服务器 4个月前420
图解Raft算法:大数据分布式系统一致性协议入门教程(超详细) 假设你有一个大数据系统,用3台服务器(节点)存用户的订单数据。节点故障:比如服务器A宕机,服务器B和C的数据可能不一样,用户查订单时会得到错误结果;网络延迟:服务器A给B发了“新增订单”的命令,但B没... 国内服务器 4个月前420
Hadoop 安装与搭建全流程教学【全网最全超详细保姆级教学】 本文是面向零基础读者的 Hadoop 3 节点集群保姆级安装教程,详细讲解基于 CentOS 7 系统从虚拟机创建、静态 IP 配置、JDK 与 Hadoop 安装,到 SSH 互信搭建、集群配置文件... 国内服务器 4个月前420