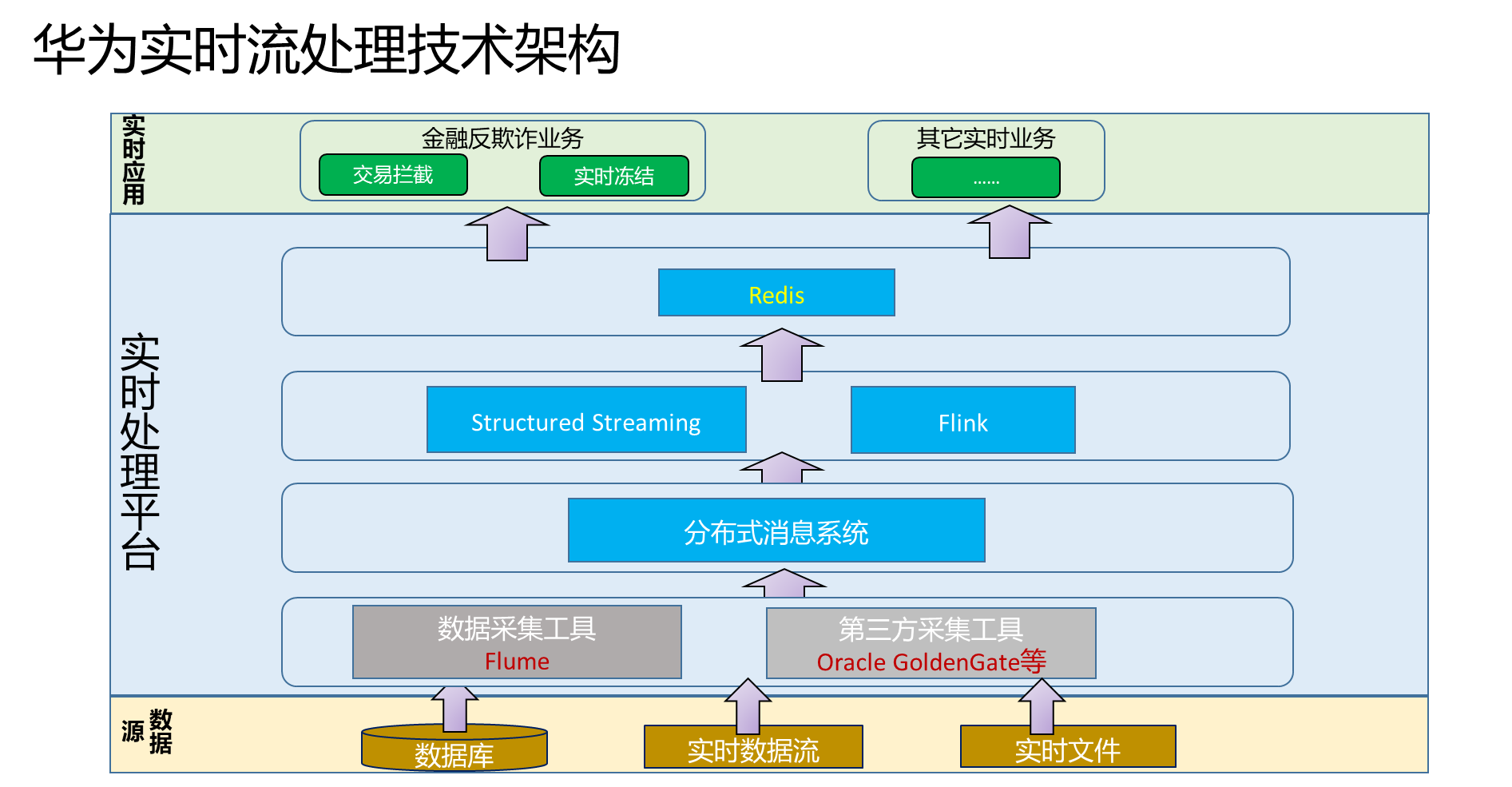
【117页PPT】大数据实时流处理场景化解决方案:技术框架与项目实战、四大核心组件(Flume、Kafka、Flink、Structured Streaming) 定义:数据从生成、采集、缓存、计算到落地与展示的全流程在秒级甚至毫秒级内完成。核心价值:数据的价值随时间迅速衰减,实时处理能更快提供洞察,支撑业务决策。。核心能力:实时采集、低延迟计算、高可靠传输、灵... 国内服务器 2个月前200
【大数据分析 | 深度学习】在Hadoop上实现分布式深度学习 本文介绍大数据和深度学习结合之路,即在Hadoop上实现分布式深度学习。主要讲解三个框架,包括Submarine(Hadoop生态系统),TonY(LinkedIn)和DL4J(deeplearnin... 国内服务器 2个月前270
Hadoop在大数据领域的旅游数据分析案例 我是李阳,资深大数据工程师,专注于旅游、零售行业的大数据应用。曾主导过3个旅游景区的大数据项目,擅长用Hadoop、Spark解决实际问题。我的公众号“大数据启示录”会分享更多实战案例,欢迎关注。留言... 国内服务器 2个月前240
淘宝客APP数据湖架构:Iceberg + Flink实现的历史数据回溯与增量计算统一存储方案 面对每日亿级的流水记录、频繁的订单状态变更(如下单、付款、结算、失效)以及复杂的佣金追溯需求,传统的Hive数仓在ACID事务支持和实时性上显得捉襟见肘,而单纯的Kafka流处理又难以满足大规模历史数... 国内服务器 2个月前260
【Python大数据项目】基于Hadoop+Spark的高血压风险分析系统毕设选题推荐 毕业设计 选题推荐 毕设选题 数据分析 机器学习 数据挖掘 本系统围绕高血压风险预测,构建了一套完整的大数据分析流程。系统后端基于Python与Django,核心计算引擎采用Hadoop与Spark,对海量健康数据进行清洗、转换与多维度分析。研究内容涵盖人群基... 国内服务器 2个月前210
AKHQ:颠覆传统的Apache Kafka可视化管理神器 对于任何使用Apache Kafka的开发者和运维人员来说,高效的管理工具是提升生产力的关键。AKHQ作为一款专业的Kafka GUI管理工具,为您提供了前所未有的可视化操作体验,让复杂的Kafka集... 国内服务器 2个月前230
RabbitMQ整合springboot 本文介绍了RabbitMQ与SpringBoot的整合方法,重点讲解了fanout和direct两种模式。整合方式包括配置类创建和注解创建两种。以fanout模式为例,详细说明了整合步骤:1)引入依赖... 国内服务器 2个月前200
云原生与边缘计算融合驱动下一代互联网架构创新探索实践【六十六】 云原生与边缘计算的结合,使互联网系统从“中心化”走向“分布式智能”。通过容器、微服务与轻量化集群技术,我们可以构建高性能、低延迟的现代应用架构。 国内服务器 2个月前260
如何5分钟找回压缩包密码:ArchivePasswordTestTool终极指南 你是否曾经因为忘记重要压缩包的密码而焦虑不安?那些珍贵的照片、重要的工作文档,就因为一个密码而被困在压缩包中无法访问。别担心,ArchivePasswordTestTool正是为你量身定制的解决方案... 国内服务器 2个月前230