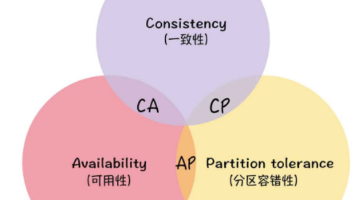
【SpringCloud】注册中心 && 服务注册 && 服务发现 && Eureka 本文介绍了微服务架构中的注册中心概念及其核心作用。注册中心作为服务实例的"地址簿",实现了服务的动态发现,解决了硬编码URL的问题。文章阐述了注册中心的三种角色(服... 国内服务器 2个月前240
Kubernetes–在k8s中安装和使用kafka Apache Kafka 作为当今最流行的分布式流处理平台之一,已被广泛应用于实时数据管道、事件驱动架构和流分析等场景。随着云原生技术的普及,在 Kubernetes 上运行 Kafka 已成为主流选... 国内服务器 2个月前230
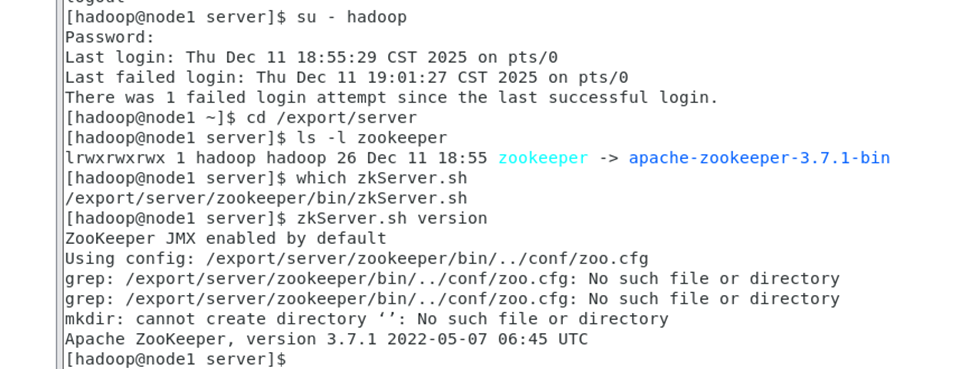
ZooKeeper三节点集群搭建出现的问题和解决过程 export/server/zookeeper/bin/zkServer.sh start && echo "node1已启动"/export/server/zoo... 国内服务器 2个月前240
人工智能与大数据专业人工智能与大数据专业选题题目合集 | 推荐系统/自然语言处理/图像识别【选题汇总】 人工智能与大数据专业毕业设计的主要研究方向,包括智能推荐系统、自然语言处理、图像识别与处理、数据分析与可视化、机器学习算法优化、智能交通系统以及情感分析,并为每个方向提供了具体的研究内容和技术实现建议... 国内服务器 2个月前250
【信息科学与工程学】【数据科学】【大数据与数据治理】第三十篇 大数据杀熟01【违法违规,审计专用】 技术体系完备:大数据杀熟涉及从数据采集、用户画像、价格敏感度分析、动态定价到差异化展示的完整技术链条,需要多种算法的综合应用。算法复杂性高:涉及机器学习、深度学习、强化学习、优化算法、统计模型等多种算... 国内服务器 2个月前800
2026大数据毕设选题推荐:基于Hadoop的猫眼电影票房可视化分析系统 本文介绍了一个基于猫眼电影数据的大数据分析与可视化系统。该系统采用Hadoop生态作为底层框架,结合PySpark进行分布式处理,实现了对电影票房数据的多维度挖掘。系统从15个关键维度分析电影基础信息... 国内服务器 2个月前250
基于神经网络的学生学习情况分析系统-hadoop+django 摘要:本研究开发了一个基于Python+Django框架的学生学习分析系统,采用B/S架构和MySQL数据库,通过LSTM算法实现成绩预测。系统包含用户管理、学习数据分析、成绩预测和可视化展示等功能模... 国内服务器 2个月前250
MGeo模型与Flink实时流结合:动态地址匹配系统架构实战 本文介绍了基于星图GPU平台自动化部署MGeo地址相似度匹配实体对齐-中文-地址领域镜像的实践,结合Flink实时流处理技术,构建动态地址匹配系统。该方案广泛应用于订单风控、配送路径优化等场景,实现高... 国内服务器 2个月前210
【大数据毕业设计推荐】Spark+Django起点小说网大数据可视化分析系统源码 毕业设计 选题推荐 毕设选题 数据分析 机器学习 本项目基于Spark+Django构建了一个起点小说网数据可视化分析系统,利用Hadoop与Spark技术对海量小说数据进行高效处理。系统实现了从类别分布、作者能力到商业化程度等多维度的数据分析,并通... 国内服务器 2个月前240
RabbitMQ 中 Ready 和 Unacked 到底是什么意思?如何用它们判断系统是否健康 摘要:RabbitMQ中的Ready和Unacked指标是判断系统健康的关键指标。Ready表示队列中待消费的消息数量,其持续增长反映消费能力不足;Unacked表示已投递但未确认的消息数量,高值可能... 国内服务器 2个月前240