缓存穿透、缓存击穿、缓存雪崩都有哪些常见处理? 本文总结了缓存穿透、击穿和雪崩三种常见缓存问题的解决方案。对于缓存穿透,建议参数校验、缓存空值、使用布隆过滤器拦截无效请求;缓存击穿可通过永不过期热点数据、互斥锁限流和服务降级处理;缓存雪崩则推荐错开... 国内服务器 2个月前230
基于Spark的大规模数据集成处理实战教程 在数字化时代,企业数据像“爆炸的烟花”——来源多(日志、数据库、IoT设备)、格式杂(CSV/JSON/关系表)、规模大(TB级甚至PB级)。传统工具(如Python脚本、Excel)处理这类数据时... 国内服务器 2个月前280
Springboot结合RabbitMQ实现延时队列 RabbitMQ实现延时队列的两种方案比较 摘要:本文介绍了RabbitMQ实现延时队列的两种方案。方案一利用死信交换机(DLX)和消息TTL机制,无需插件但存在队头阻塞问题,且需要为不同延迟时间创建... 国内服务器 2个月前210
《Windows Internals》10.1.11 应用程序 Hive(Application hives):为什么 Windows 要允许应用拥有“只对自己可见”的私有注册表? Windows 7引入的应用程序Hive(Application hives)机制为应用提供了私有注册表空间,解决了传统注册表访问的公共性问题。通过RegSaveKeyEx和RegLoadAppKey... 国内服务器 2个月前240
【大数据毕设源码分享】基于springboot+数据可视化的舆情热点话题分析管理系统的设计与实现(程序+文档+代码讲解+一条龙定制) 主要内容:免费开题报告、任务书、全bao定制+中期检查PPT、代码编写、🚢文编写和辅导、🚢文降重、长期答辩答疑辅导、一对一专业代码讲解辅导答辩、模拟答辩演练、和理解代码逻辑思路。 国内服务器 2个月前290
计算机毕业设计Hadoop+PySpark+Scrapy爬虫考研分数线预测 考研院校推荐系统 考研推荐系统 考研(源码+文档+PPT+讲解) 摘要:本研究提出基于Hadoop+PySpark+Scrapy的分布式考研分数线预测系统,整合研招网等12类数据源构建20+维特征矩阵。采用混合预测模型(Prophet+XGBoost+BiLSTM... 国内服务器 2个月前250
震撼来袭!大数据行式存储的技术变革 想象一下,在当今数字化时代,每天全球都会产生海量的数据,从社交媒体上的用户动态,到电商平台的交易记录,再到医疗领域的患者信息。这些数据如同浩瀚宇宙中的繁星,数量庞大且不断增长。假设我们是数据的“星际探... 国内服务器 2个月前220
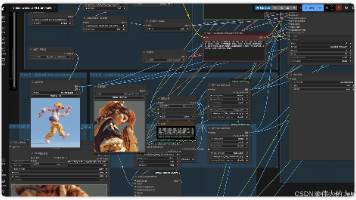
ComfyUI 部署 Wan 2.2 Animate 14B (MoE) 满血版:NVIDIA DGX Spark 128G VRAM 摘要:本文展示了在NVIDIA DGX Spark环境下使用Wan 2.2 Animate 14B模型的工作流程,包含视频预处理、SAM2模型加载、图像缩放控制等关键节点。完整工作流文件支持视频输入处... 国内服务器 2个月前350
深入了解大数据领域数据科学的传感器数据处理 本文旨在为读者提供关于传感器数据处理的全面指南,涵盖从基础概念到高级技术的各个方面。我们将重点讨论大数据环境下的传感器数据处理挑战和解决方案。文章首先介绍传感器数据的基本概念和特性,然后详细讲解数据处... 国内服务器 2个月前230
踩过坑才明白:为什么 ZooKeeper 集群才是正经事 本文详细介绍了ZooKeeper集群的搭建过程。首先通过三台虚拟机配置主机名、关闭防火墙、设置IP地址等环境准备工作。接着在三台机器上安装ZooKeeper,配置zoo.cfg文件并创建数据目录。重点... 国内服务器 2个月前410