前端静态资源指纹化:Hash 策略与缓存更新的协同设计 内容变则文件名变,文件名变则缓存自然失效,缓存失效则用户自然拿到新版本。HTML 作为入口不做长缓存,静态资源因为文件名包含 contenthash 可以放心缓存一年。Query String 方案有... 国内服务器 6天前70
一文搞懂Flink乱序数据 + Watermark 乱序数据产生的核心原因:司机端网络波动(高速、偏远地区)、设备缓存、数据传输链路延迟,是货运平台的常态;用少量的实时性牺牲(5秒),换取数据统计的准确性,让基于「司机真实点击时间」的事件时间统计有实际... 国内服务器 6天前90
Java 集合框架八股:从全景架构到 HashMap 连环追问 对比维度JDK 7JDK 8数据结构Segment[] + HashEntry[] + 链表Node[] + 链表 + 红黑树(对齐 HashMap)同步机制ReentrantLock(分段锁)CAS... 国内服务器 1周前110
Kafka 是什么?深入解析分布式事件流平台的核心原理与应用场景 Apache Kafka 是一个开源的分布式事件流平台,由 LinkedIn 公司于 2011 年开发,随后捐赠给 Apache 软件基金会并成为顶级开源项目。它最初被设计用于处理 LinkedIn ... 国内服务器 1周前60
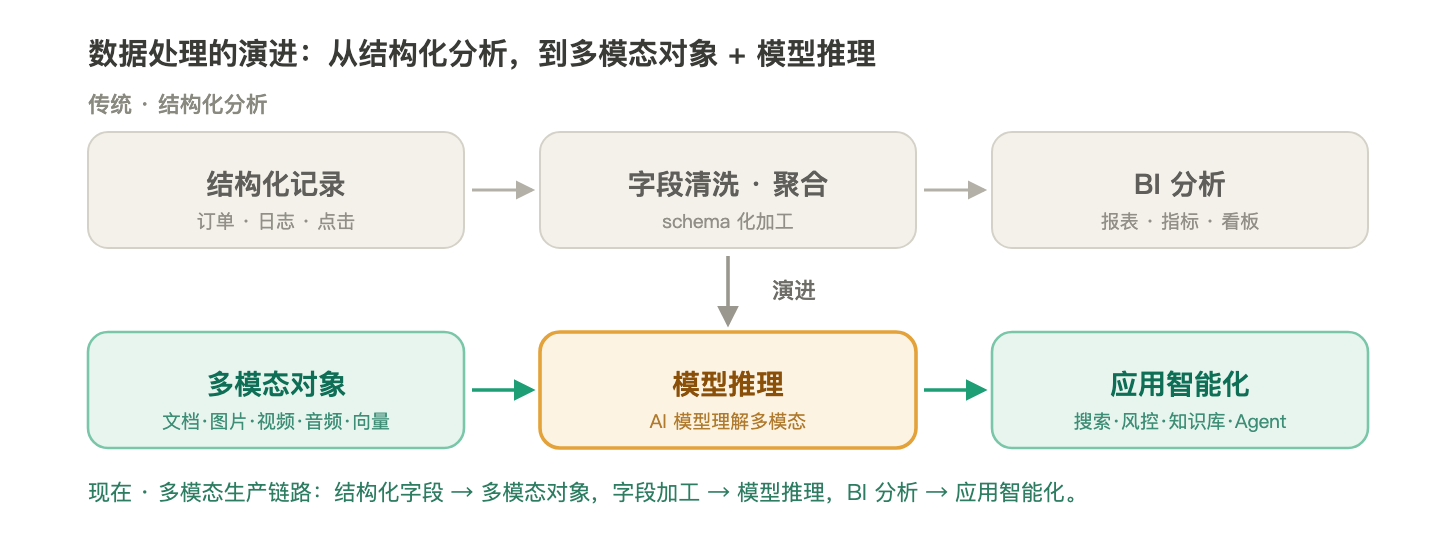
从结构化到多模态:Apache Flink,多模态数据处理的流式底座 过去很长一段时间里,数据处理系统主要围绕结构化记录展开:订单、日志、点击、交易、指标、维表、事实表。数据被抽象成一行行 schema 清晰的记录,核心任务是清洗、关联、聚合、统计。这类链路支撑了搜索... 国内服务器 1周前140
SpringBoot 地铁 ISCS 实战第十二篇:上位智能采集器设计|OPC UA 采集层 + Kafka 消息队列统一转发落地实战 本文提出了一种基于OPC UA和Kafka的地铁综合监控系统上位智能采集器解决方案,实现了采集与业务完全解耦的工业级数据采集架构。该方案通过四层结构:现场设备层、统一采集总线层、上位智能采集器层和业务... 国内服务器 1周前70
一文搞懂hadoop的HDFS Hadoop是由Apache基金会所开发的分布式系统基础架构,旨在解决海量数据存储和计算分析问题。狭义上来说,Hadoop是指Apache Hadoop开源框架,包含以下三种核心组件:广义上来说,Ha... 国内服务器 1周前70
PyUSB数据传输完全指南:控制、批量、中断、等时四种传输模式 PyUSB是一款功能强大的Python库,为开发者提供了简单易用的USB设备访问接口。本文将详细介绍PyUSB支持的四种USB数据传输模式——控制传输、批量传输、中断传输和等时传输,帮助你轻松掌握各类... 国内服务器 1周前60
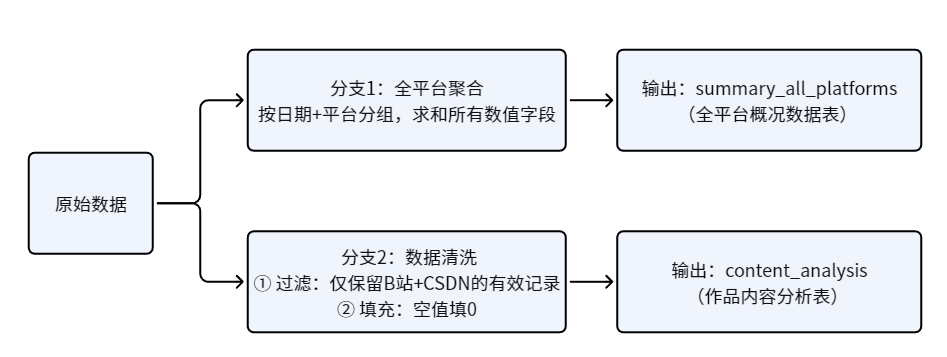
【大数据实验】基于助睿ETL实现自媒体运营数据清洗与预处理 摘要: 本次实验利用助睿ETL零代码工具对多平台自媒体互动数据进行清洗与预处理。通过双分支处理设计,分别输出全平台汇总统计表(保留原始数据)和重点平台(B站、CSDN)精细化明细表(剔除无效记录、填充... 国内服务器 1周前80
在Rocky Linux9.8系统上安装Hive Hive 3.1.3安装指南(基于Hadoop 3.x和MySQL 8.0) 本文详细介绍在双节点集群(Master/Slave)上安装Hive 3.1.3的步骤: MySQL安装:通过YUM仓库安装... 国内服务器 1周前90