Kafka HW与LEO深度解析:副本同步核心指标 每个副本的最后一条消息的offset + 1,即下一条将要写入消息的offset。fill:#333;important;important;fill:none;color:#333;color:#3... 国内服务器 2个月前330
运用大数据领域时序分析优化供应链管理 促销活动前备货太多,导致库存积压半年;突发的节日需求激增,仓库缺货引发客户投诉;物流时效波动大,明明提前发货却还是延误;靠Excel趋势线做预测,结果和实际偏差20%以上。这些问题的核心,在于传统供应... 国内服务器 2个月前250
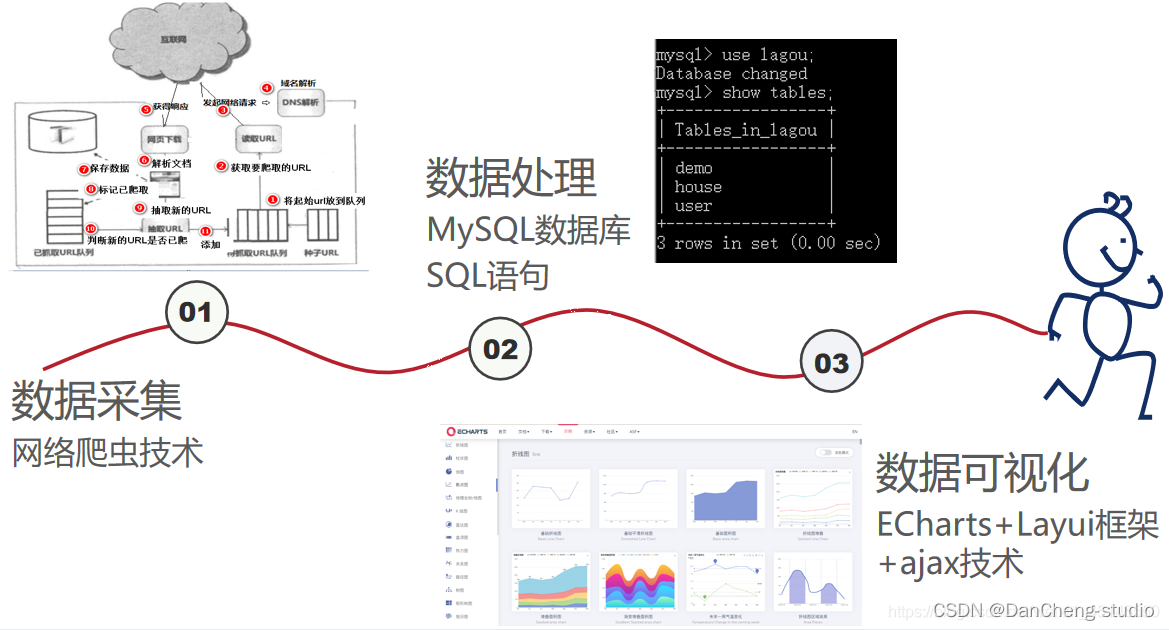
毕业设计 基于大数据的招聘与租房分析可视化系统 本文介绍了一个基于大数据的招聘与租房分析可视化系统。系统采用Python爬虫技术抓取拉勾网和链家等平台的招聘和租房数据,通过Ajax技术实现前后端交互,利用Echarts进行数据可视化展示。项目包含数... 国内服务器 2个月前290
Kafka Consumer Group 详解:原理、机制与应用实践 在分布式消息系统中,如何高效地消费消息是一个核心问题。Apache Kafka 通过Consumer Group(消费者组)这一精妙的设计,完美解决了多个消费者协同消费、负载均衡、故障转移等问题。本文... 国内服务器 2个月前210
Eureka 在大数据计算中的应用实践 Eureka 作为轻量级服务发现框架,完美适配大数据场景的「分布式、动态、高可用」需求。通过本文的实践,你已经掌握了 Eureka 在 Spark、Flink、Hadoop YARN 中的落地方法,以... 国内服务器 2个月前290
《Windows Internals》10.1.20 Hive structure:为什么一个 Hive 在内部不是“键和值的平铺集合”,而是 block、base block、bin、cell 这种 本文解析了Windows注册表Hive的分层存储结构,指出其并非简单的键值平铺集合。Hive内部采用4KB block作为基础存储单元,首个base block存储全局元信息(如regf签名、校验和等... 国内服务器 2个月前310
存储系统的容量规划与管理:从预测到优化 存储容量规划是指根据业务需求和数据增长趋势,预测存储系统的容量需求,并制定相应的扩容和管理策略的过程。满足需求:确保存储容量能够满足业务需求避免浪费:避免过度配置,减少资源浪费优化成本:优化存储成本... 国内服务器 2个月前270
Hadoop容错机制深度解析:从单点故障到集群自愈 fill:#333;important;important;fill:none;Hadoop容错体系数据容错副本机制数据块校验自动复制计算容错任务重试推测执行节点迁移服务容错ZooKeeper仲裁应用... 国内服务器 2个月前260
大数据领域数据预处理的质量评估指标 数据预处理是大数据项目中最耗时且关键的环节,据统计,数据科学家80%的时间都花费在数据清洗和预处理上。本文旨在系统性地介绍数据预处理阶段的质量评估指标体系,帮助读者建立科学的数据质量评估框架。核心概念... 国内服务器 2个月前280