MongoDB内存配置终极指南:大数据环境下避免OOM的实战经验 MongoDB作为大数据时代最流行的文档数据库,其性能高度依赖内存配置。本文从第一性原理出发,系统拆解MongoDB的内存模型(WiredTiger缓存、文件系统缓存、进程内存),结合Linux操作系... 国内服务器 4个月前380
基于大数据的人力资源招聘数据分析与可视化 本文基于Java开发环境,采用Spring Boot框架构建了一个大数据招聘分析平台。系统整合了爬虫技术采集多源招聘数据,利用Hadoop分布式存储处理海量信息,并通过Python可视化工具进行交互展... 国内服务器 4个月前380
大学生HTML期末大作业——HTML+CSS+JavaScript购物商城(丝芙兰) HTML+CSS+JS【购物商城】网页设计期末课程大作业 web前端开发技术 web课程设计 网页规划与设计 国内服务器 4个月前380
Archivematica开源数字保存系统:从零开始构建专业档案管理平台 面对数字时代的海量文件,如何确保重要文档能够长期保存并保持可访问性?Archivematica作为一款免费开源的数字保存系统,提供了基于标准的长期数字保存解决方案。本文将带你从项目结构解析到实际工作流... 国内服务器 4个月前380
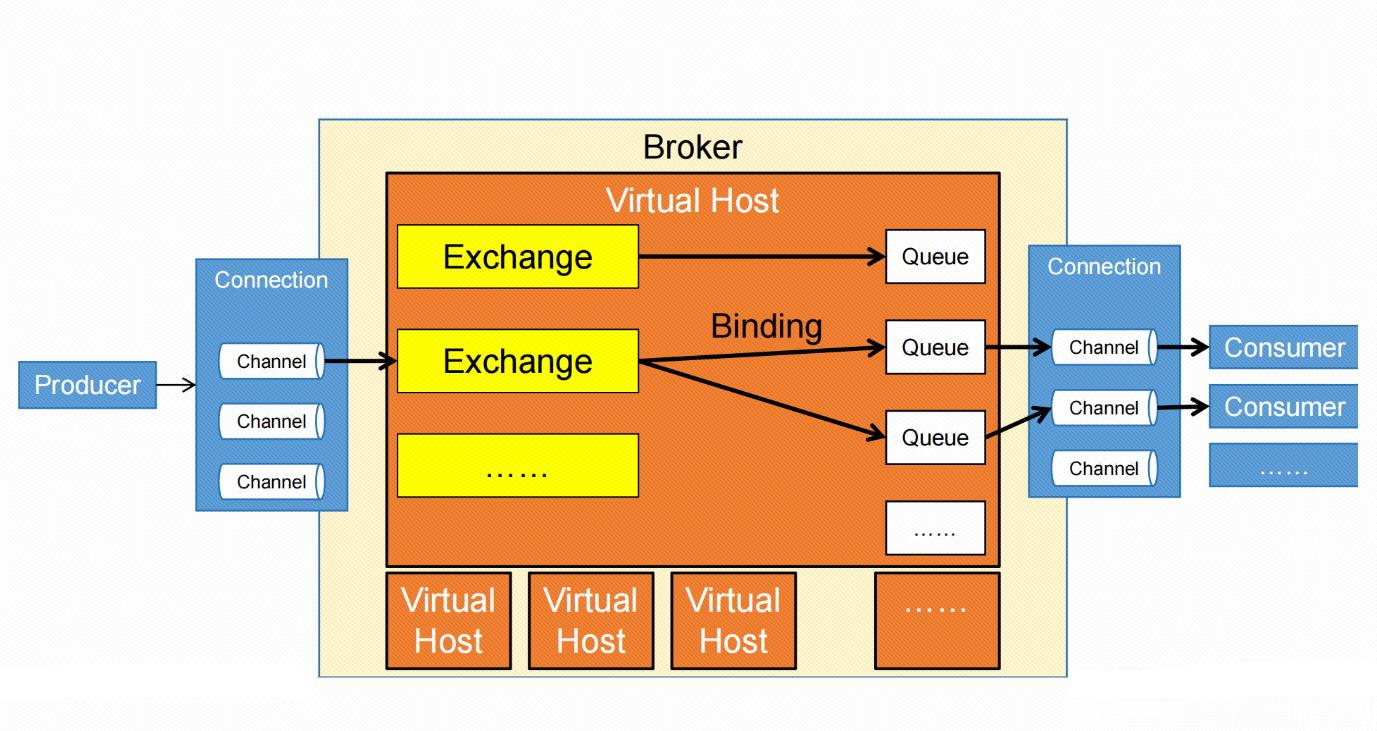
后端-RabbitMQ RabbitMQ是一种基于AMQP协议的消息队列中间件,支持异步消息传递。AMQP协议定义了Broker、Virtual host、Connection、Channel、Exchange、Queue等... 国内服务器 4个月前380
计算机毕业设计hadoop+spark+hive在线教育可视化 课程推荐系统 大数据毕业设计(源码+LW文档+PPT+讲解) 摘要:本文介绍了一个基于Hadoop+Spark+Hive的在线教育大数据可视化平台设计方案。该平台整合了大数据处理技术与可视化技术,旨在解决教育领域PB级数据的存储、分析和实时可视化需求。研究内容包... 国内服务器 4个月前380
Flink原理与实战(java版)#第11章Flink的应用(第三节Table & SQL 连接器之Hive(九)) 介绍Hive作为Table API和SQL的外部连接器使用,并且结合实际应用中会使用kafka作为数据源进行介绍。 国内服务器 5个月前380
IEEE ISPA大数据并行算法 本文深入探讨IEEE ISPA研讨会中的大数据并行算法核心技术,涵盖PRAM、MapReduce、BSP和Dataflow四种并行模型,分析其适用场景与优劣。同时介绍任务调度机制、数据与模型并行策略... 国内服务器 5个月前380
Zenodo高效科研数据管理实战指南:从零开始构建专业数据仓库 还在为科研数据的管理和共享而困扰吗?Zenodo作为专业的科研数据管理平台,为你提供完整的数据存储、DOI分配和版本控制解决方案,让科研工作更加高效有序。掌握Zenodo科研数据管理技巧,你将能够轻松... 国内服务器 3个月前370