J002 Vue+SpringBoot电影推荐可视化系统|双协同过滤推荐算法评论情感分析spark数据分析|配套文档1.34万字 本文介绍了一个基于Vue.js和Spring Boot的智能电影推荐系统。系统采用B/S架构,前端使用Vue.js构建响应式界面,后端基于Spring Boot提供RESTful API服务。核心功能... 国内服务器 5个月前370
HiSpark嵌入式第一课 介绍了海思芯片及其相关开发工具,重点讲解了如何使用HiSpark Studio进行星闪技术的开发与测距实验。使用ws63芯片的开发板,首先概述了海思芯片的产品矩阵。随后,介绍了HiSpark Stud... 国内服务器 2个月前360
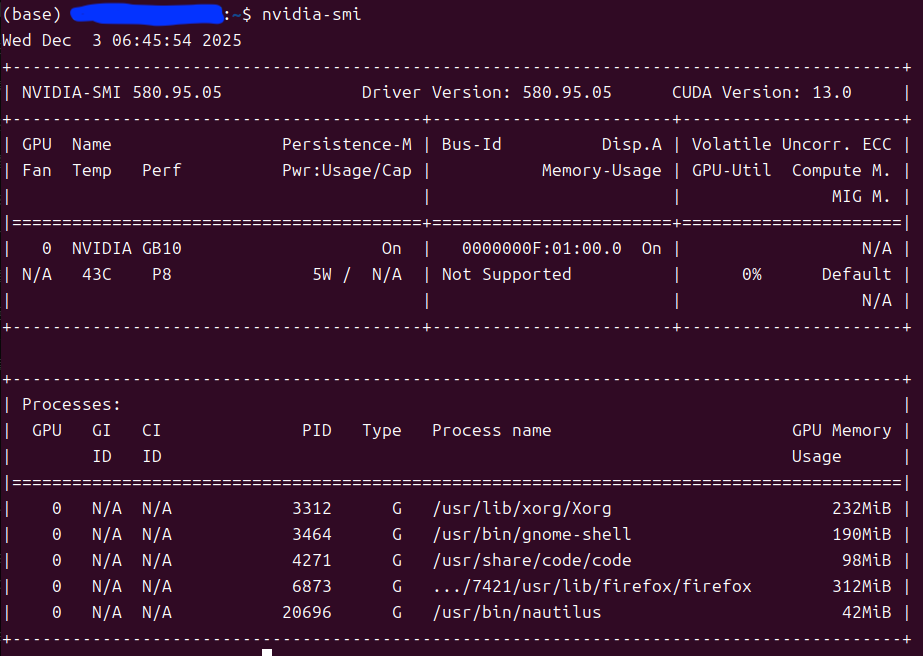
DGX-spark-GB10 120GB显存的机器,为什么部署Qwen3-14B生成速率才13tokens/s 摘要:Qwen3-14B Q8_0模型13t/s的速度属于正常范围,主要受限于DGXSpark的显存带宽(~273GB/s)。Dense架构大模型在推理阶段是内存带宽受限,而非算力受限。提升方案包括... 国内服务器 3个月前360
NVIDIA DGX Spark(Ubuntu24.04)安装isaacsim和isaaclab+ros2 isaacsim和isaaclab有三种安装方法:源码编译,二进制编译,pip安装。源码编译会有非常非常非常多的bug,而且速度很慢,不建议尝试。pip安装速度最快,可参照我的这篇文章pip在NVID... 国内服务器 3个月前360
数据仓库与数据湖:大数据运营的存储架构对比 在大数据时代,企业面临的最大挑战之一是如何高效存储、管理和利用多源异构的数据市场部门需要分析结构化的销售报表(SQL友好);算法团队需要处理非结构化的用户行为日志、图片/视频(灵活存储);管理层需要快... 国内服务器 3个月前360
Eureka助力大数据领域的服务发现的容错设计 随着大数据技术栈(如Hadoop、Spark、Flink)的普及,分布式系统规模呈指数级增长。典型的大数据平台包含成百上千个服务节点(数据节点、计算节点、协调节点),服务间依赖关系复杂,节点故障概率随... 国内服务器 3个月前360
Windows 下 Kafka 安装教程(保姆级) Kafka 是基于 Java 的,必须先安装 JDK。一般学到kafka的同学肯定已经安装好了JDK了,这一步我就不写了,具体可以参考其他文章。⚠️ 不要直接关闭 CMD 窗口也不要ctrl + c... 国内服务器 3个月前360
Java语言提供了八种基本类型hh 变量就是申请内存来存储值。也就是说,当创建变量的时候,需要在内存中申请空间。内存管理系统根据变量的类型为变量分配存储空间,分配的空间只能用来储存该类型数据。因此,通过定义不同类型的变量,可以在内存中储... 国内服务器 3个月前360
卡夫卡(Kafka)从入门到实践:超详细学习指南 卡夫卡是由 Apache 软件基金会开发的分布式流处理平台,最初由 LinkedIn 公司设计,用于解决大规模日志收集与传输问题。它的核心定位是 “高吞吐量的分布式发布 - 订阅消息系统”,具有高吞吐... 国内服务器 4个月前360



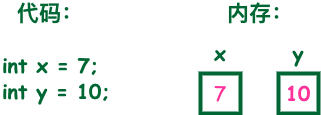
![[C++][第三方库][RabbitMq]详细讲解](https://os.v.madlive.cn/idcmadlive/2026/03/b243bc25ff10408a872764c01a2dbf33.png)
