基于SpringBoot+大数据爬虫Hadoop+智能AI大模型的抖音女装推荐系统的设计与实现(精品源码+精品论文+上万数据集+答辩PPT) 随着互联网技术的飞速发展和移动互联网的普及,电商行业迎来了前所未有的机遇和挑战。尤其是在短视频平台的崛起下,抖音等平台成为了消费者购物和分享生活的重要渠道。女装作为电商平台中最受欢迎的品类之一,其市场... 国内服务器 4个月前350
C++图论算法实战精解 $ \text{入度} \operatorname{deg}^{-}(v) = 0 \implies \text{可移除} $$:实际编码需处理边界条件(如不连通图、自环边),建议使用C++ STL的... 国内服务器 5个月前350
2026高职大数据与财务管理专业学数据分析的技术价值分析 根据行业调研,超过70%的财务岗位要求候选人具备基础数据分析能力,如SQL查询或可视化工具操作。测试表明,经过80学时的专项训练,75%的学生可独立完成方差分析。典型招聘需求显示,财务数据分析岗的薪资... 国内服务器 2个月前340
Dubbo- 注册中心实战:Zookeeper 部署与 Dubbo 集成配置 摘要:本文详细介绍了Dubbo与Zookeeper的集成实践,从注册中心的核心作用到Zookeeper单机/集群部署配置。主要内容包括: 注册中心原理:阐述Zookeeper如何通过临时节点、Watc... 国内服务器 3个月前340
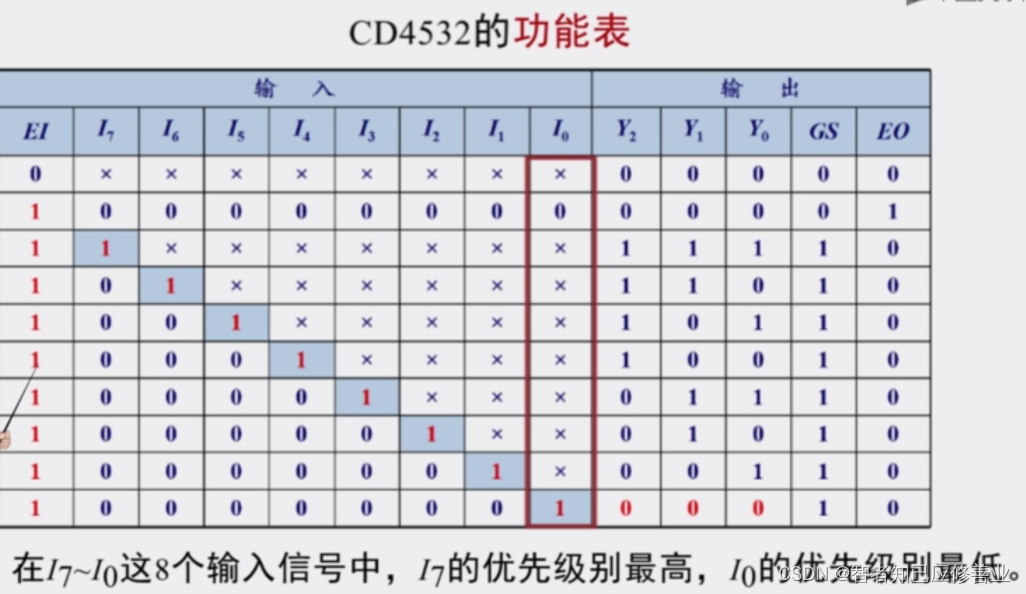
【CD4532/74HC147/74HC283组成的9线BCD编码器加减法器】2023-4-18 该内容讨论了基于74HC147、74HC283等芯片的电路设计应用。74HC147是10线-4线优先编码器,可将9个输入编码为BCD码输出;74HC283是4位二进制全加器。文中提到使用CD4532... 国内服务器 3个月前340
Flink SQL INSERT 语句单表写入、多表分流、分区覆盖与 StatementSet Flink SQL 中的 INSERT 语句用于将数据写入目标表,支持多种灵活用法。主要功能包括:1)通过 executeSql 立即提交单条 INSERT 作业,或使用 StatementSet 批... 国内服务器 3个月前340
腾讯云 AI 视觉计费系统如何利用 Flink 状态管理实现精准去重 本文详细解析了腾讯云AI视觉计费系统如何利用Flink状态管理实现精准去重,涵盖RocksDB状态后端、TTL机制、复合Key策略等核心技术。通过优化Checkpoint配置和两阶段提交,系统每天处理... 国内服务器 3个月前340
基于Python大数据旅游数据分析与推荐系统的爬虫 数据分析可视化系统 该系统基于Python技术栈构建,整合了网络爬虫、大数据分析、机器学习推荐算法及可视化技术,旨在为旅游行业提供数据驱动的决策支持与个性化服务。数据采集层采用Scrapy框架爬取主流旅游平台(如携程、T... 国内服务器 3个月前340
Hive SQL中COALESCE 函数和NVL()函数、IFNULL函数区别 Hive 中的NVL()是双参数函数,用于将 NULL 值替换为指定的非 NULL 值,语法和行为与 Oracle 的NVL()完全兼容。语法作用:如果expression为 NULL,则返回repl... 国内服务器 3个月前340