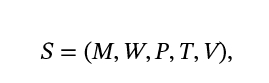Hadoop 核心技术深度解析:从架构原理到实战应用 本文深度解析Hadoop 3.x核心技术体系,涵盖分布式存储(HDFS)、计算框架(MapReduce)和资源调度(YARN)三大核心组件。重点探讨了3.x版本的关键升级:HDFS支持多NameNod... 国内服务器 2周前90
返利APP实时分佣统计:Kafka Streams与窗口计算在T+0佣金结算中的Exactly-Once语义保障 省赚客APP研发团队基于Kafka Streams构建了实时分佣引擎,利用滑动窗口计算与Exactly-Once(精确一次)语义,打造了金融级的实时清算系统。通过引入Kafka Streams的 Ex... 国内服务器 2周前80
数据仓库测试方法论:确保大数据质量的完整方案 验收测试是业务人员对数据质量的最终确认。验证DM层的报表是否符合业务需求(如“日销售额”是否与手工统计一致);确认指标定义是否清晰(如“活跃用户”的口径是否与业务理解一致);检查报表的可读性(如字段名... 国内服务器 2周前80
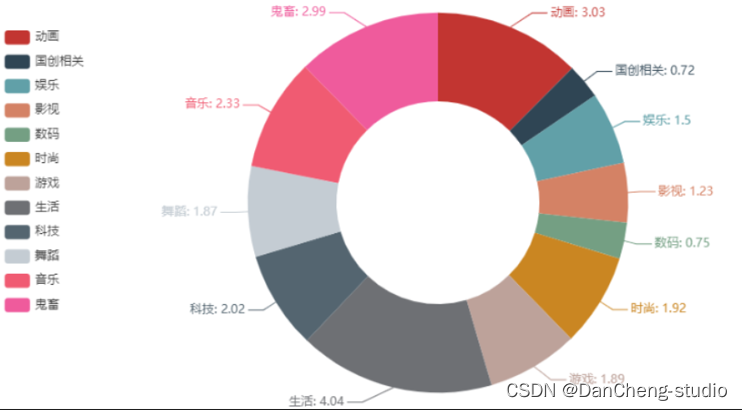
基于大数据的b站数据分析 本文主要运用Python的第三方库SnowNLP对弹幕内容进行情感分析,使用方法很简单,计算出的情感score表示语义积极的概率,越接近0情感表现越消极,越接近1情感表现越积极。从数据可视化中可以看到... 国内服务器 2周前90
消息队列深度对比:Kafka vs RabbitMQ vs RocketMQ vs Pulsar vs NATS,选型 + 实战 + 性能调优 本文系统对比主流消息队列 Kafka、RabbitMQ、RocketMQ、Pulsar 和 NATS JetStream 的核心差异。从架构设计、功能特性、性能表现到使用场景进行全方位分析,提供生产级... 国内服务器 2周前80
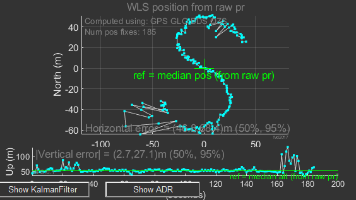
【GNSS】 Android GNSS数据采集入门:GNSSLogger完整配置指南 本文介绍了Android GNSS数据采集工具GNSSLogger的配置与使用方法。主要内容包括:GNSSLogger的功能特点(支持原始GNSS测量、GnssStatus、NMEA等数据记录);设备... 国内服务器 2周前100
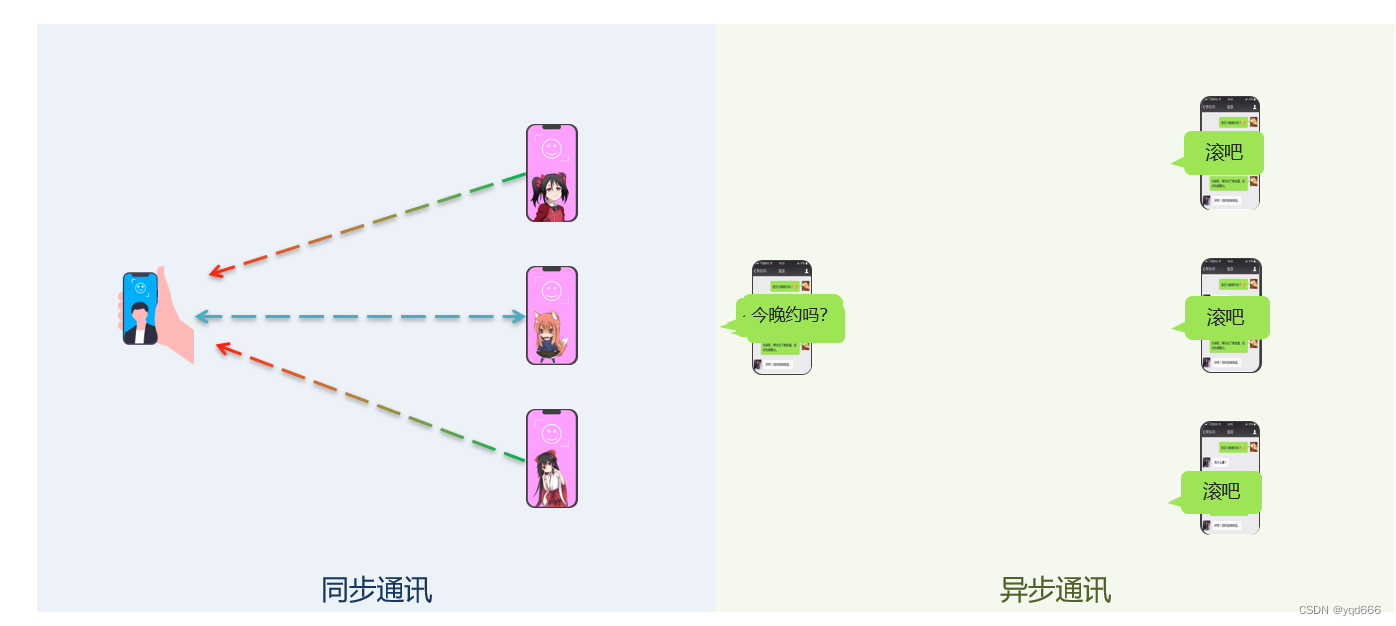
RabbitMQ用法 本文介绍了消息队列(MQ)的核心概念与应用场景,对比了同步通讯和异步通讯的优缺点,并详细讲解了RabbitMQ的安装配置与SpringAMQP的使用方法。 同步vs异步通讯: 同步通讯时效性强但耦合度... 国内服务器 2周前90
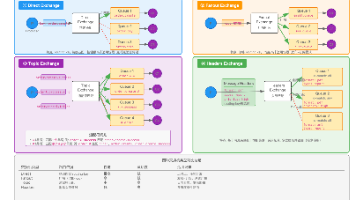
RabbitMQ核心技术深度解析 RabbitMQ是一个基于AMQP协议的开源消息代理系统,采用Erlang开发,具有灵活路由、高可靠性等优势。其核心架构包含生产者、交换机、队列和消费者等组件,支持多种交换机类型(Direct、Fan... 国内服务器 2周前180
Agent Skill Security:威胁模型、攻击、防御与评估 大家读完觉得有帮助记得关注和点赞!!!摘要可复用技能正成为大语言模型(LLM)智能体的基础构件,使得各类能力能够被封装、共享并跨应用场景复用。然而,现有安全研究主要聚焦于提示注入与运行时执行,对更广泛... 国内服务器 2周前80
从学术研究到工业应用:Replica Dataset的10大创新点解析 Replica Dataset是一个高质量的室内空间重建数据集,包含多种室内场景的精细几何结构、高分辨率高动态范围纹理、玻璃和镜面表面信息、平面分割以及语义类别和实例分割。它不仅为学术研究提供了丰富的... 国内服务器 2周前90