HBase架构深度解析:HMaster、RegionServer与ZooKeeper三驾马车 fill:#333;important;important;fill:none;root(HBase架构精髓)HMaster元数据管理负载均衡故障恢复数据读写Region管理ZooKeeper集群协调... 国内服务器 1周前70
java-springboot基于大数据的电子商务信用评估系统 基于SpringBoot+Vue的电商用户信用画像与风险预警系统 前后端分离的在线交易信用评分与可视化分析平台计算机毕业设计 摘要:本文介绍了一个基于Java-SpringBoot和大数据技术的电子商务信用评估系统。该系统采用B/S架构,整合Hadoop处理PB级交易数据,通过协同过滤和梯度提升树双模型融合,实现秒级信用评分... 国内服务器 2周前90
ES与Kafka集成实现实时处理从零实现 手把手带你从零搭建Elasticsearch与Kafka的实时数据通道,解决日志同步、指标消费和流式索引难题;利用Kafka的高吞吐与ES的近实时搜索能力,构建低延迟、可扩展的实时处理链路,重点覆盖e... 国内服务器 1周前100
Hadoop作业调度策略深度解析:从原理到生产选型指南 明确业务需求:是否需要资源隔离?是否有SLA要求?评估集群规模:小规模测试可用FIFO,生产集群必选Capacity/Fair考虑负载类型:单一负载选Capacity,混合负载选Fair权衡管理成本... 国内服务器 2周前110
大数据领域的教育行业实践 随着教育数字化转型加速,海量教育数据(如学习行为日志、教学资源元数据、学业成绩数据等)的积累催生了对大数据技术的迫切需求。本文聚焦大数据在教育行业的落地实践,涵盖数据全生命周期管理(采集→存储→处理... 国内服务器 1周前100
HarmonyOS应用开发实战:萌宠日记 – 备份恢复能力集成 页面预览前言数据备份与恢复 是移动应用不可或缺的基础能力,它保障用户数据在 换机迁移、应用重装、系统恢复 等场景下的安全性和连续性。在 萌宠日记 中,我们通过 ExtensionAbility 的 b 国内服务器 2周前170
【Spark 核心内参】2026.2:Spark 4.0.2 发布与 GitHub Issues 迁移大讨论 【Spark 核心内参】2026.2:Spark 4.0.2 发布与 GitHub Issues 迁移大讨论 航向追踪 Apache Spark 4.0.2 重要指数: ⭐⭐⭐⭐ 关键更... 国内服务器 2周前140
极客星闪 | 筑基:轻量级方案之 VS Code + HiSpark 插件开发环境搭建 本文档介绍在 Windows 下通过 VS Code 配合 HiSpark Studio 扩展插件搭建开发环境的完整流程。该方案具备轻量化、易操作的特点,涵盖从软件安装到源码编译、镜像烧录及串口监控的... 国内服务器 2周前130
Hadoop输入格式深度解析:默认输入格式与自定义实战 在Hadoop MapReduce框架中,输入格式(InputFormat) 是数据处理的起点,它决定了如何读取、分割和解析输入数据。正确选择或设计输入格式,直接影响作业的并行度、数据本地性和处理效率... 国内服务器 2周前130
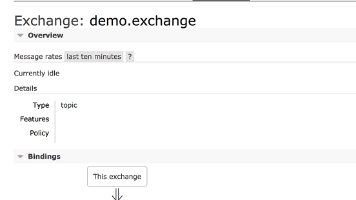
在 ASP.NET Core 中使用(消费) RabbitMQ 消息 本文介绍了在ASP.NET Core中使用BackgroundService消费RabbitMQ消息的方法。首先通过Docker快速搭建RabbitMQ环境,然后创建继承自BackgroundServ... 国内服务器 2周前100