
LangChain实战:工具调用+结构化输出,让AI从“聊天“变“干活“
文章目录
-
- 工具调用(Tool Calling)
-
- 1.Tool创建的三种方式
-
- 1.1. **直接用 `@tool` 装饰函数**
- 1.2. **用 `@tool` + 自定义参数结构(Pydantic)**
- 1.3. **继承 `BaseTool` 写类**
- 2. 本地自定义工具
-
- 2.1 定义工具
- 2.2 绑定工具到模型
- 2.3 工具调用流程
- 2.4 AI 响应结构解析
- 3. 第三方工具集成(Tavily搜索([https://www.tavily.com/](https://www.tavily.com/)))
-
- 3.1 集成第三方工具
- 3.2 多轮工具调用
- 3.3 实际输出示例
- 结构化输出(Structured Output)
-
- 1. Pydantic BaseModel(推荐)
-
- 1.1 定义 Pydantic 模型
- 1.2 绑定结构化输出
- 1.3 输出示例
- 2. TypedDict
-
- 2.1 定义 TypedDict
- 2.2 使用 TypedDict
- 2.3 输出示例
- 3. JSON Schema
-
- 3.1 定义 JSON Schema
- 3.2 使用 JSON Schema
- 3.3 输出示例
- 4. 可选结构化输出(动态类型选择)
-
- 4.1 应用场景
- 4.2 实现方式
- 4.3 使用示例
- 4.4 输出示例
- 4.5 关键特性
- 4.6 优势
- 结构化输出的三大实际应用场景
-
- 场景1:作为信息提取器 – 将非结构化文本转化为结构化数据
-
- 核心价值
- 典型应用
- 实现示例:简历信息提取
- 场景2:作为提示词增强 – 帮助 AI 更好理解用户意图
-
- 核心价值
- 典型应用
- 实现示例:搜索意图理解
- 场景3:与 Tool 联合使用 – 结构化输出 + 工具调用的完美组合
-
- 核心价值
- 典型应用
- 实现示例:智能天气助手(工具调用 + 结构化输出整合)
- 三大场景对比总结
-
- 选择建议
- 四种结构化输出方式对比总结
- 参考资源

工具调用(Tool Calling)
工具调用是 LangChain 的核心功能之一,允许 AI 模型调用外部函数或 API 来完成特定任务。
例如,当我们希望获取当前天⽓情况时,由于LLM⽆法获取实时信息,此时我们就可以借助⼯具,通过外部服务进⾏搜索完成查询:
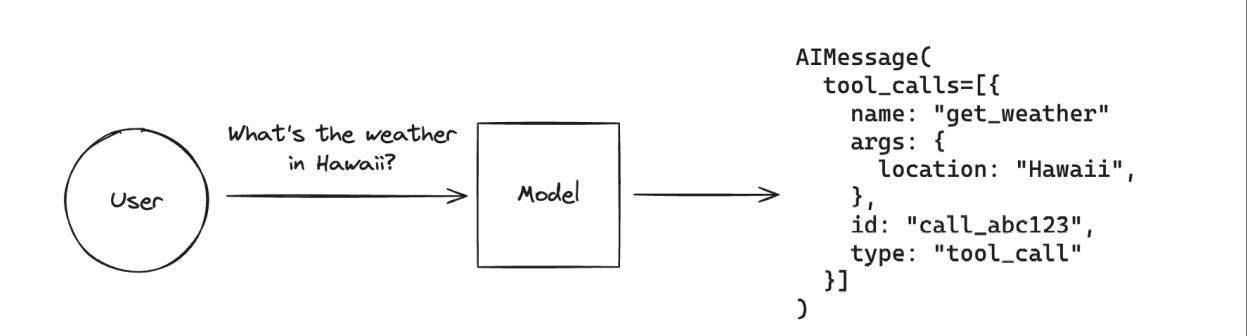
再例如,当我们希望获取数据库表中的数据时,由于LLM⽆法直接获取表数据,此时我们就可以借助⼯具,通过与数据库交互完成查询:
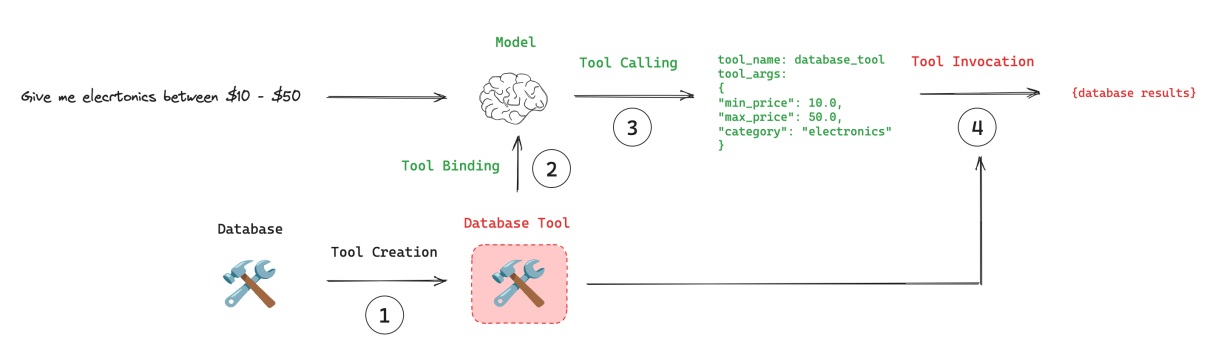
1.Tool创建的三种方式
1.1. 直接用 @tool 装饰函数
最简单,适合小工具
@tool
def add(a: int, b: int) -> int:
return a + b
1.2. 用 @tool + 自定义参数结构(Pydantic)
参数更清晰,能写详细说明
@tool(args_schema=AddInput)
def add(a: int, b: int) -> int:
return a + b
1.3. 继承 BaseTool 写类
最灵活,适合复杂或异步操作(比如调 API)
class AddTool(BaseTool):
def _run(self, a: int, b: int):
return a + b
2. 本地自定义工具
示例文件: simple_@tool.py
2.1 定义工具
使用 @tool 装饰器定义一个本地工具:
from langchain_core.tools import tool
@tool
def sum_to_n(n: int) -> int:
"""计算从0累加到n的结果"""
sum = 0
for i in range(n+1):
sum += i
return sum
关键点:
- 使用
@tool装饰器标记函数 - 函数必须有类型注解(
n: int和-> int) - 文档字符串(docstring)会被模型用来理解工具的功能
2.2 绑定工具到模型
from langchain.chat_models import init_chat_model
llm = init_chat_model(
model="deepseek-chat",
model_provider="deepseek",
api_key="your-api-key",
temperature=0.7,
max_tokens=8192,
)
# 绑定工具
bound_llm = llm.bind_tools([sum_to_n])
关键点:
-
bind_tools()方法将工具绑定到模型 - 可以绑定多个工具:
bind_tools([tool1, tool2, tool3]) - 当然我们也可以让模型强制调⽤⼯具,那就需要在绑定⼯具时,设置 tool_choice=“any” ,表⽰强制调⽤⾄少⼀个⼯具。
2.3 工具调用流程
from langchain_core.messages import HumanMessage, SystemMessage, ToolMessage
# 1. 构建用户消息
message = [
SystemMessage(content="你是一个数学助手。当用户给你一个数字n时,使用sum_to_n工具计算从0累加到n的结果。"),
HumanMessage(content="10"),
]
# 2. 模型决定是否调用工具
ai_message = bound_llm.invoke(message)
message.append(ai_message)
# 3. 执行工具调用
for tool_call in ai_message.tool_calls:
if tool_call["name"] == "sum_to_n":
result = sum_to_n.invoke(tool_call["args"])
message.append(
ToolMessage(
content=str(result),
tool_call_id=tool_call["id"]
)
)
# 4. 获取最终回复
final_msg = bound_llm.invoke(message).content
print(final_msg)
工作流程图:
用户输入 → AI分析 → 决定调用工具 → 执行工具 → 返回结果 → AI生成最终回答
2.4 AI 响应结构解析
当模型决定调用工具时,ai_message 包含以下关键信息:
# ai_message 结构(经过 LangChain 框架整合)
{
'content': '我来计算从0累加到10的结果。',
'tool_calls': [
{
'name': 'sum_to_n', # 工具名称
'args': {'n': 10}, # 工具参数
'id': 'call_00_xxx', # 调用ID
'type': 'tool_call'
}
],
'response_metadata': {
'token_usage': {...},
'model_name': 'deepseek-chat',
'finish_reason': 'tool_calls' # 表示模型决定调用工具
}
}
重要提示:
-
ai_message是经过 LangChain 框架整合后的响应,不是模型的原始输出 -
tool_calls列表包含模型决定调用的所有工具 - 必须使用
ToolMessage包装工具执行结果,并提供tool_call_id
3. 第三方工具集成(Tavily搜索(https://www.tavily.com/))
示例文件: tavily_tool.py
3.1 集成第三方工具
from langchain_tavily import TavilySearch
# 创建 Tavily 搜索工具
tavily_tool = TavilySearch(
max_results=4,
tavily_api_key="your-tavily-api-key"
)
# 绑定到模型
bound_llm = llm_tavily.bind_tools([tavily_tool])
关键点:
- 第三方工具通常需要 API Key
- 参数名必须正确(如
tavily_api_key而不是api_key)
3.2 多轮工具调用
有时模型可能需要多次调用工具才能得到满意的结果:
message = [
SystemMessage(content="你是一个天气助手。使用tavily_search工具搜索天气情况。"),
HumanMessage(content="2026年3月2日北京天气情况"),
]
# 工具调用循环(最多3轮)
max_rounds = 3
for round_num in range(1, max_rounds + 1):
# 调用模型
ai_message = bound_llm.invoke(message)
message.append(ai_message)
# 如果没有工具调用,说明得到最终答案了
if not ai_message.tool_calls:
print(ai_message.content)
break
# 执行工具调用
for tool_call in ai_message.tool_calls:
result = tavily_tool.invoke(tool_call["args"])
tool_message = ToolMessage(
content=str(result),
tool_call_id=tool_call["id"]
)
message.append(tool_message)
工作流程:
第1轮: 用户提问 → AI调用搜索工具 → 获取搜索结果
第2轮: AI分析结果 → 生成最终答案(不再调用工具)
3.3 实际输出示例
根据搜索结果,2026年3月2日北京天气情况:
白天天气:
- 天气状况:阴天,大部分地区有小雪或雨夹雪
- 风向风力:北风转南风2-3级
- 最高气温:5-6℃
夜间天气:
- 天气状况:阴天,山区有小雪
- 风向风力:南风转北风1-2级
- 最低气温:-1℃到0℃
特别预警:
北京市气象台发布大雾黄色预警信号,夜间至次日上午能见度小于1000米。
结构化输出(Structured Output)
结构化输出允许模型返回符合特定格式的数据,而不是纯文本。这对于数据提取、API 响应生成等场景非常有用。
例如,可能希望将模型输出存储在数据库中,并确保输出符合数据库模式。这种需求激发了结构化输出的概念,其中可以指⽰模型使⽤特定的输出结构进⾏响应。
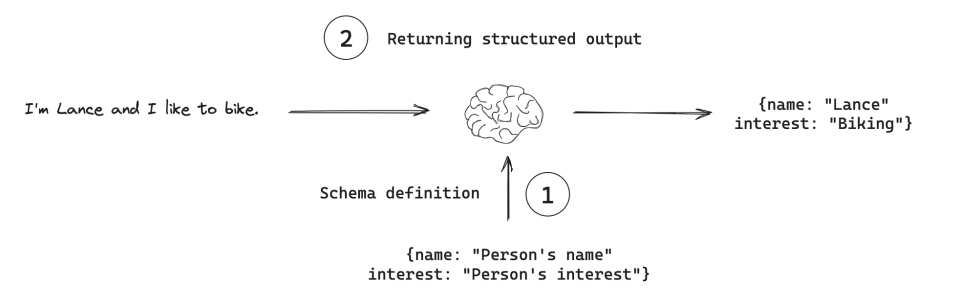
示例文件: struct_output.py
1. Pydantic BaseModel(推荐)
1.1 定义 Pydantic 模型
from pydantic import BaseModel, Field
class TestOutput(BaseModel):
"""城市信息的Pydantic模型"""
test: str = Field(description="这个城市现在的详细天气情况,包括天气状况、温度、风力等")
test2: str = Field(description="城市名称")
test3: str = Field(description="在这个城市出生的一个著名名人,包括简短介绍")
关键点:
- 继承
BaseModel - 使用
Field()添加字段描述,帮助模型理解每个字段的含义 - 支持类型验证和数据校验
1.2 绑定结构化输出
from langchain_deepseek import ChatDeepSeek
llm_deepseek = ChatDeepSeek(
model_name="deepseek-chat",
api_key="your-api-key",
base_url="https://api.deepseek.cn/v1",
)
# 绑定结构化输出
struct_output_model = llm_deepseek.with_structured_output(TestOutput)
# 调用模型
result = struct_output_model.invoke("上海")
# 访问结构化数据
print(f"天气: {result.test}")
print(f"城市: {result.test2}")
print(f"名人: {result.test3}")
1.3 输出示例
# 返回的是 Pydantic 对象
test='上海现在天气晴朗,温度25°C,东南风3-4级,湿度65%,空气质量良好'
test2='上海'
test3='姚明,中国著名篮球运动员,1980年出生于上海,曾效力于NBA休斯顿火箭队'
优点:
- 类型安全,IDE 有完整的代码提示
- 自动数据验证
- 可以使用
Field()添加详细描述 - 支持复杂的嵌套结构
缺点:
- 需要定义类
2. TypedDict
2.1 定义 TypedDict
from typing import TypedDict, Annotated
class TestOutputDict(TypedDict):
"""城市信息的字典类型"""
weather: Annotated[str, "这个城市现在的详细天气情况,包括天气状况、温度、风力等"]
city_name: Annotated[str, "城市名称"]
famous_person: Annotated[str, "在这个城市出生的一个著名名人,包括简短介绍"]
population: Annotated[int, "城市人口数量(万人)"]
关键点:
- TypedDict 不支持
Field() - 使用
Annotated[类型, "描述"]添加字段描述 - 支持不同类型(str, int, float, bool 等)
2.2 使用 TypedDict
# 绑定结构化输出
struct_output_model_dict = llm_deepseek.with_structured_output(TestOutputDict)
# 调用模型
result_dict = struct_output_model_dict.invoke("上海")
# 访问字典数据
print(f"天气: {result_dict['weather']}")
print(f"城市: {result_dict['city_name']}")
print(f"人口: {result_dict['population']} 万人")
2.3 输出示例
# 返回的是纯字典
{
'city_name': '上海',
'weather': '上海现在天气晴朗,温度18-25°C,东南风3-4级',
'population': 2487,
'famous_person': '姚明,中国著名篮球运动员,前NBA休斯顿火箭队球员'
}
优点:
- 轻量级,返回纯字典
- 不需要定义复杂的类
- 可以使用
Annotated添加描述
缺点:
- 类型检查较弱
- 不支持
Field()的高级功能
3. JSON Schema
3.1 定义 JSON Schema
import json
json_schema = {
"title": "CityInfo",
"description": "城市信息的JSON格式",
"type": "object",
"properties": {
"city": {
"type": "string",
"description": "城市名称"
},
"weather": {
"type": "string",
"description": "当前天气情况,包括温度、天气状况、风力"
},
"attractions": {
"type": "array",
"description": "城市的著名景点列表",
"items": {
"type": "string"
}
},
"gdp": {
"type": "number",
"description": "城市GDP(亿元)"
}
},
"required": ["city", "weather", "attractions", "gdp"]
}
关键点:
- 使用标准的 JSON Schema 格式
- 支持复杂的嵌套结构(数组、对象等)
-
required字段指定必填项
3.2 使用 JSON Schema
# 绑定结构化输出
struct_output_model_json = llm_deepseek.with_structured_output(json_schema)
# 调用模型
result_json = struct_output_model_json.invoke("北京")
# 格式化输出
print(json.dumps(result_json, ensure_ascii=False, indent=2))
3.3 输出示例
{
"city": "北京",
"weather": "晴,温度15°C,风力2级",
"attractions": [
"故宫",
"天安门广场",
"长城",
"颐和园",
"天坛",
"圆明园"
],
"gdp": 40269.6
}
优点:
- 标准化,跨语言通用
- 支持复杂的嵌套结构
- 灵活,可以定义任意结构
缺点:
- 定义较繁琐
- 没有 IDE 类型提示
- 返回的是 dict,不是 JSON 字符串
4. 可选结构化输出(动态类型选择)
示例文件: choice_struct.py
4.1 应用场景
当你需要模型根据用户输入自动选择返回不同类型的结构化数据时,可以使用可选结构化输出。这在以下场景非常有用:
- 智能客服系统:根据用户问题返回不同类型的信息(人物、产品、订单等)
- 信息提取系统:从文本中提取不同类型的实体
- 多功能 API:一个接口根据请求返回不同格式的数据
4.2 实现方式
使用 Literal 类型和嵌套的 Pydantic 模型:
from pydantic import BaseModel, Field
from typing import Literal
# 定义不同的数据结构
class PersonInfo(BaseModel):
"""人物信息"""
name: str = Field(description="姓名")
age: int = Field(description="年龄")
occupation: str = Field(description="职业")
class CityInfo(BaseModel):
"""城市信息"""
city: str = Field(description="城市名称")
population: int = Field(description="人口(万人)")
class NormalAnswer(BaseModel):
"""普通回答"""
answer: str = Field(description="根据用户的提问正常答复的内容")
# 定义包装类,让模型选择返回类型
class Response(BaseModel):
"""响应结构,模型根据问题选择返回人物、城市信息或普通回答"""
type: Literal["person", "city", "normal"] = Field(
description="响应类型:person表示人物,city表示城市,normal表示普通回答"
)
person: PersonInfo | None = Field(default=None, description="人物信息,仅当type为person时填充")
city: CityInfo | None = Field(default=None, description="城市信息,仅当type为city时填充")
normal: NormalAnswer | None = Field(default=None, description="普通回答,仅当type为normal时填充")
# 把这些pydantic class 合并到一个union class中
#class UnionInfo(BaseModel):
#"""联合信息"""
# union: Union[PersonInfo, CityInfo, normal_answer]
4.3 使用示例
from langchain_deepseek import ChatDeepSeek
llm = ChatDeepSeek(
model_name="deepseek-chat",
api_key="your-api-key",
base_url="https://api.deepseek.cn/v1",
)
# 绑定结构化输出
model = llm.with_structured_output(Response)
# 测试1:询问城市
result1 = model.invoke("上海")
if result1.type == "city":
print(f"城市: {result1.city.city}")
print(f"人口: {result1.city.population}万")
# 测试2:普通问题
result2 = model.invoke("你是哪个模型")
if result2.type == "normal":
print(f"回答: {result2.normal.answer}")
4.4 输出示例
测试1(城市):
类型: city
城市: 上海
人口: 2489万
测试2(普通问题):
类型: normal
回答: 我是DeepSeek最新版本的AI助手,由深度求索公司开发...
4.5 关键特性
-
Literal类型:限定模型只能选择预定义的类型值 -
可选字段:使用
| None和default=None表示字段可选 - 嵌套结构:不同的数据类型作为子结构嵌套在包装类中
- 模型自主决策:AI 根据问题内容自动判断应该返回哪种结构
4.6 优势
- 灵活性高:一个接口处理多种类型的请求
-
类型明确:通过
type字段清楚知道返回的数据类型 -
易于扩展:可以轻松添加更多类型(如
"product","order"等) - 代码简洁:不需要多个不同的接口或函数
结构化输出的三大实际应用场景
场景1:作为信息提取器 – 将非结构化文本转化为结构化数据
核心价值
结构化输出最直接的应用就是信息提取:将杂乱无章的文本数据转换为规范的结构化数据,便于存储、查询和分析。
典型应用
- 简历解析:从PDF/Word简历中提取姓名、联系方式、教育经历、工作经验
- 合同分析:提取合同中的关键条款、金额、日期、甲乙方信息
- 发票识别:从发票图片OCR文本中提取发票号、金额、税额、日期
- 新闻摘要:从新闻文章中提取标题、摘要、关键人物、时间地点
实现示例:简历信息提取
from pydantic import BaseModel, Field
class Education(BaseModel):
"""教育经历"""
school: str = Field(description="学校名称")
degree: str = Field(description="学位:本科、硕士、博士等")
major: str = Field(description="专业")
start_year: int = Field(description="入学年份")
end_year: int = Field(description="毕业年份")
class WorkExperience(BaseModel):
"""工作经历"""
company: str = Field(description="公司名称")
position: str = Field(description="职位")
start_date: str = Field(description="入职日期")
end_date: str = Field(description="离职日期,如果是当前工作则为'至今'")
responsibilities: list[str] = Field(description="主要职责列表")
class ResumeInfo(BaseModel):
"""简历信息"""
name: str = Field(description="姓名")
phone: str = Field(description="电话")
email: str = Field(description="邮箱")
education: list[Education] = Field(description="教育经历列表")
work_experience: list[WorkExperience] = Field(description="工作经历列表")
skills: list[str] = Field(description="技能列表")
# 使用示例
model = llm.with_structured_output(ResumeInfo)
resume_text = """
张三,电话:138****1234,邮箱:zhangsan@example.com
教育背景:
- 2015-2019 清华大学 计算机科学与技术 本科
- 2019-2021 清华大学 人工智能 硕士
工作经历:
- 2021.07-2023.06 字节跳动 算法工程师
负责推荐系统开发,优化点击率提升20%
- 2023.07-至今 阿里巴巴 高级算法工程师
负责大模型应用开发
技能:Python, PyTorch, LangChain, 机器学习
"""
result = model.invoke(f"请从以下简历中提取信息:n{resume_text}")
# 提取后的结构化数据可以直接存入数据库
print(f"姓名: {result.name}")
print(f"联系方式: {result.phone} / {result.email}")
print(f"教育经历: {len(result.education)} 条")
print(f"工作经历: {len(result.work_experience)} 条")
print(f"技能: {', '.join(result.skills)}")
实际输出:
姓名: 张三
联系方式: 138****1234 / zhangsan@example.com
教育经历: 2 条
工作经历: 2 条
技能: Python, PyTorch, LangChain, 机器学习
关键优势:
- 自动化数据录入:无需人工逐字段复制粘贴
- 格式标准化:统一的数据格式便于后续处理
- 提高准确性:AI理解上下文,减少人工错误
- 可扩展性强:轻松添加新字段或修改提取规则
场景2:作为提示词增强 – 帮助 AI 更好理解用户意图
核心价值
通过结构化输出,可以让 AI 先理解、再执行。将用户的模糊需求转换为明确的结构化指令,确保 AI 准确理解用户意图。
典型应用
- 搜索意图识别:理解用户搜索的真实意图(查询、购买、比较、学习)
- 任务分解:将复杂任务拆解为多个子任务
- 参数提取:从自然语言中提取API调用所需的参数
- 多轮对话管理:理解对话上下文和用户当前状态
实现示例:搜索意图理解
from pydantic import BaseModel, Field
from typing import Literal
class SearchIntent(BaseModel):
"""搜索意图分析"""
intent_type: Literal["informational", "transactional", "navigational", "comparison"] = Field(
description="意图类型:informational(查询信息)、transactional(购买交易)、navigational(导航访问)、comparison(对比比较)"
)
keywords: list[str] = Field(description="提取的关键词列表")
filters: dict[str, str] = Field(description="筛选条件,如价格范围、品牌、地区等")
urgency: Literal["low", "medium", "high"] = Field(description="紧急程度")
clarification_needed: bool = Field(description="是否需要进一步澄清")
suggested_questions: list[str] = Field(description="建议的澄清问题列表")
# 使用示例
model = llm.with_structured_output(SearchIntent)
user_query = "我想买个性价比高的笔记本电脑,预算5000左右,主要用来写代码"
# 第一步:理解用户意图
intent = model.invoke(f"分析以下用户需求:{user_query}")
print(f"意图类型: {intent.intent_type}")
print(f"关键词: {', '.join(intent.keywords)}")
print(f"筛选条件: {intent.filters}")
print(f"紧急程度: {intent.urgency}")
# 第二步:根据理解的意图执行精准搜索
if intent.intent_type == "transactional":
# 执行购买导向的搜索
search_params = {
"category": "笔记本电脑",
"price_range": intent.filters.get("price_range", ""),
"keywords": intent.keywords,
"sort_by": "price_performance_ratio"
}
print(f"n执行搜索: {search_params}")
elif intent.clarification_needed:
# 需要进一步澄清
print(f"n需要澄清的问题:")
for q in intent.suggested_questions:
print(f" - {q}")
实际输出:
意图类型: transactional
关键词: 笔记本电脑, 性价比, 写代码, 编程
筛选条件: {'price_range': '4000-6000', 'usage': '编程开发', 'priority': '性价比'}
紧急程度: medium
执行搜索: {
'category': '笔记本电脑',
'price_range': '4000-6000',
'keywords': ['笔记本电脑', '性价比', '写代码', '编程'],
'sort_by': 'price_performance_ratio'
}
关键优势:
- 意图明确化:将模糊需求转换为明确的结构化指令
- 减少误解:AI先理解再执行,避免答非所问
- 提高准确性:基于结构化理解执行后续操作
- 可追溯性:清楚知道AI是如何理解用户需求的
场景3:与 Tool 联合使用 – 结构化输出 + 工具调用的完美组合
核心价值
结构化输出与工具调用结合,可以实现智能决策 + 精准执行:AI先分析需求并输出结构化决策,然后调用相应工具执行。
典型应用
- 智能助手:理解用户指令 → 决定调用哪些工具 → 执行并返回结果
- 自动化工作流:分析任务 → 规划步骤 → 依次调用工具完成
- 数据分析:理解分析需求 → 调用数据查询工具 → 结构化返回分析结果
- 多工具协作:一个任务需要多个工具配合完成
实现示例:智能天气助手(工具调用 + 结构化输出整合)
from langchain.chat_models import init_chat_model
from langchain_tavily import TavilySearch
from pydantic import BaseModel, Field
# 初始化模型
llm_tavily = init_chat_model(
model="deepseek-chat",
model_provider="deepseek",
api_key="your-api-key",
temperature=0.7,
max_tokens=8192,
)
# 创建搜索工具
tavily_tool = TavilySearch(
max_results=4,
tavily_api_key="your-tavily-api-key"
)
# 定义结构化输出格式
class WeatherResult(BaseModel):
"""天气查询结果"""
location: str = Field(description="地点")
date: str = Field(description="日期")
temperature: str = Field(description="温度范围")
weather: str = Field(description="天气状况")
wind: str = Field(description="风力风向")
warning: str = Field(description="预警信息,如果没有则为'无'")
# 步骤1:先绑定工具
bound_llm = llm_tavily.bind_tools([tavily_tool])
# 步骤2:再绑定结构化输出
structured_llm = bound_llm.with_structured_output(WeatherResult)
# 步骤3:直接调用,自动完成工具调用和结构化输出
result = structured_llm.invoke("2026年3月2日北京天气情况")
# 输出结构化结果
print(f"地点: {result.location}")
print(f"日期: {result.date}")
print(f"温度: {result.temperature}")
print(f"天气: {result.weather}")
print(f"风力: {result.wind}")
print(f"预警: {result.warning}")
实际输出:
地点: 北京
日期: 2026年3月2日
温度: -1℃到6℃
天气: 阴天,有小雪或雨夹雪
风力: 北风转南风2-3级,夜间南风转北风1-2级
预警: 大雾黄色预警,能见度小于1000米
关键优势:
- 智能决策:结构化输出帮助AI理解需求并做出决策
- 精准执行:基于结构化决策调用合适的工具
- 结果规范:工具返回的数据再次结构化,便于使用
- 流程清晰:理解 → 决策 → 执行 → 返回,每步都可追溯
三大场景对比总结
| 场景 | 核心价值 | 主要用途 | 典型应用 | 技术特点 |
|---|---|---|---|---|
| 信息提取器 | 非结构化 → 结构化 | 数据提取与转换 | 简历解析、合同分析、发票识别 | 单向转换、数据标准化 |
| 提示词增强 | 模糊意图 → 明确指令 | 意图理解与澄清 | 搜索优化、任务分解、参数提取 | 双向交互、意图明确化 |
| Tool联合使用 | 智能决策 + 精准执行 | 复杂任务自动化 | 智能助手、自动化工作流、数据分析 | 多步骤、工具协作 |
选择建议
-
需要类型灵活切换 → 使用可选结构化输出(
choice_struct.py模式) - 固定的数据提取 → 使用单一 Pydantic 模型
- 复杂嵌套结构 → 使用 JSON Schema 或嵌套 Pydantic 模型
- 简单键值对 → 使用 TypedDict
四种结构化输出方式对比总结
| 方式 | 优点 | 缺点 | 适用场景 | 返回类型 |
|---|---|---|---|---|
| Pydantic BaseModel | 类型安全、字段验证、IDE支持好、可使用Field | 需要定义类 | 复杂数据结构、需要验证 | Pydantic对象 |
| TypedDict | 轻量级、返回纯字典、使用Annotated添加描述 | 类型检查较弱、不支持Field | 简单字典结构 | dict |
| JSON Schema | 标准化、跨语言、灵活、支持复杂嵌套 | 定义繁琐、无IDE提示 | 跨系统对接、复杂嵌套 | dict |
| 可选结构化输出 | 灵活性高、类型明确、易扩展、代码简洁 | 需要定义包装类 | 多类型动态响应 | Pydantic对象 |
参考资源
- LangChain 官方文档
- Pydantic 文档
- JSON Schema 规范
- Tavily API 文档
© 版权声明
文章版权归作者所有,未经允许请勿转载。


