
【大数据基础】大数据处理架构Hadoop:02 Hadoop生态系统

【作者主页】Francek Chen
【专栏介绍】
⌈
⌈
⌈大数据技术原理与应用
⌋
⌋
⌋专栏系统介绍大数据的相关知识,分为大数据基础篇、大数据存储与管理篇、大数据处理与分析篇、大数据应用篇。内容包含大数据概述、大数据处理架构Hadoop、分布式文件系统HDFS、分布式数据库HBase、NoSQL数据库、云数据库、MapReduce、Hadoop再探讨、数据仓库Hive、Spark、流计算、Flink、图计算、数据可视化,以及大数据在互联网领域、生物医学领域的应用和大数据的其他应用。
【GitCode】专栏资源保存在我的GitCode仓库:https://gitcode.com/Morse_Chen/BigData_principle_application。
文章目录
-
- 前言
- 一、HDFS
- 二、HBase
- 三、MapReduce
- 四、Hive
- 五、Pig
- 六、Mahout
- 七、ZooKeeper
- 八、Flume
- 九、Sqoop
- 十、Ambari
- 小结
前言
经过多年的发展,Hadoop 生态系统不断完善和成熟,目前已经包含了多个子项目。除了核心的 HDFS 和 MapReduce 以外,Hadoop 生态系统还包括 ZooKeeper、HBase、Hive、Pig、Mahout、Flume、Sqoop、Ambari 等功能组件。需要说明的是,Hadoop 2.0 中新增了一些重要的组件,即 HDFS HA 和分布式资源调度管理框架 YARN 等,但是为了循序渐进地理解 Hadoop,在这里暂时不讨论这些新特性,在系统学习完 MapReduce 相关内容后,后面我们将会详细讨论从 Hadoop 1.0 到 Hadoop 2.0 的特性变化。
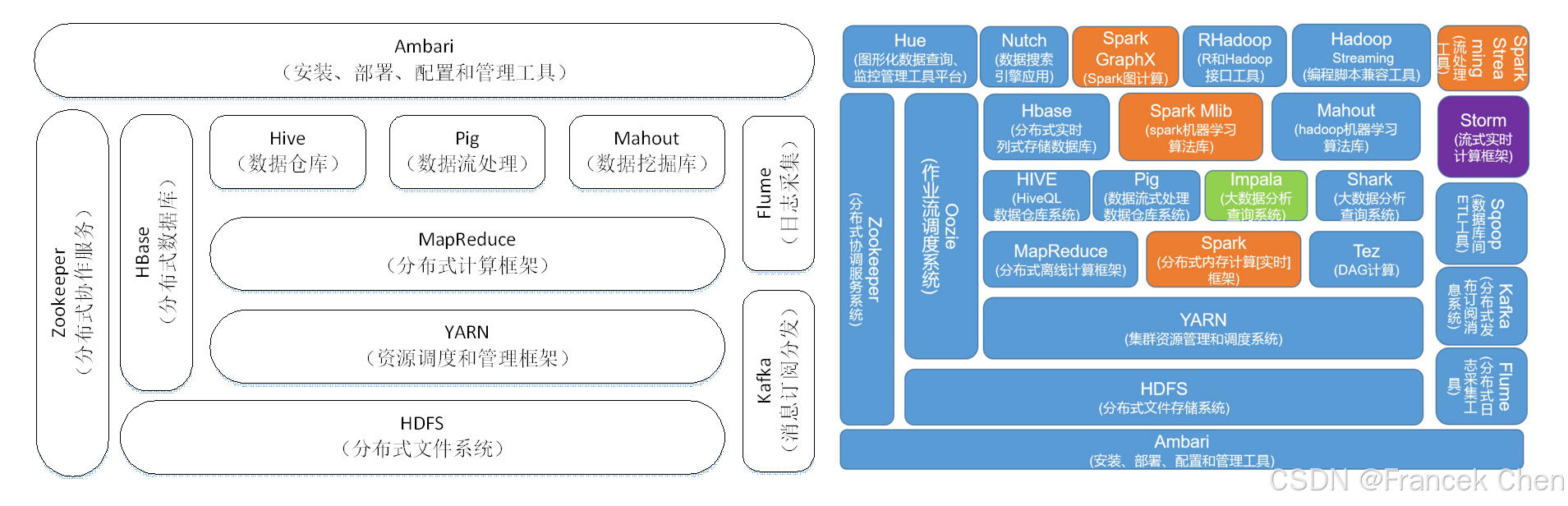
图1 Hadoop生态系统
一、HDFS
Hadoop 分布式文件系统是 Hadoop 项目的两大核心之一,是针对谷歌文件系统的开源实现。HDFS 具有处理超大数据、流式处理、可以运行在廉价商用服务器上等优点。HDFS 在设计之初就是要运行在廉价的大型服务器集群上,因此在设计上就把硬件故障作为一种常态来考虑,实现在部分硬件发生故障的情况下仍然能够保证文件系统的整体可用性和可靠性。HDFS 放宽了一部分可移植操作系统接口(Portable Operating System Interface,POSIX)约束,从而实现以流的形式访问文件系统中的数据。HDFS 在访问应用程序数据时,可以具有很高的吞吐率,因此对于超大数据集的应用程序而言,选择 HDFS 作为底层数据存储系统是较好的选择。
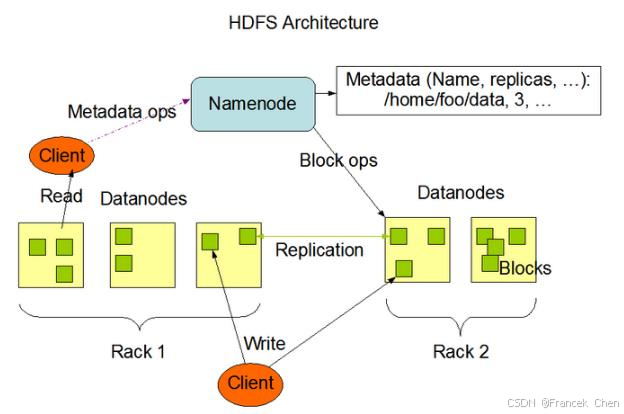
图2 HDFS架构原理
二、HBase
HBase 是一个提供高可靠性、高性能、可伸缩、实时读写、分布式的列式数据库,一般采用 HDFS 作为其底层数据存储系统。HBase 是针对谷歌 BigTable 的开源实现,二者都采用了相同的数据模型,具有强大的非结构化数据存储能力。HBase 与传统关系数据库的一个重要区别是,前者采用基于列的存储,后者采用基于行的存储。HBase 具有良好的横向扩展能力,可以通过不断增加廉价的商用服务器来提高存储能力。
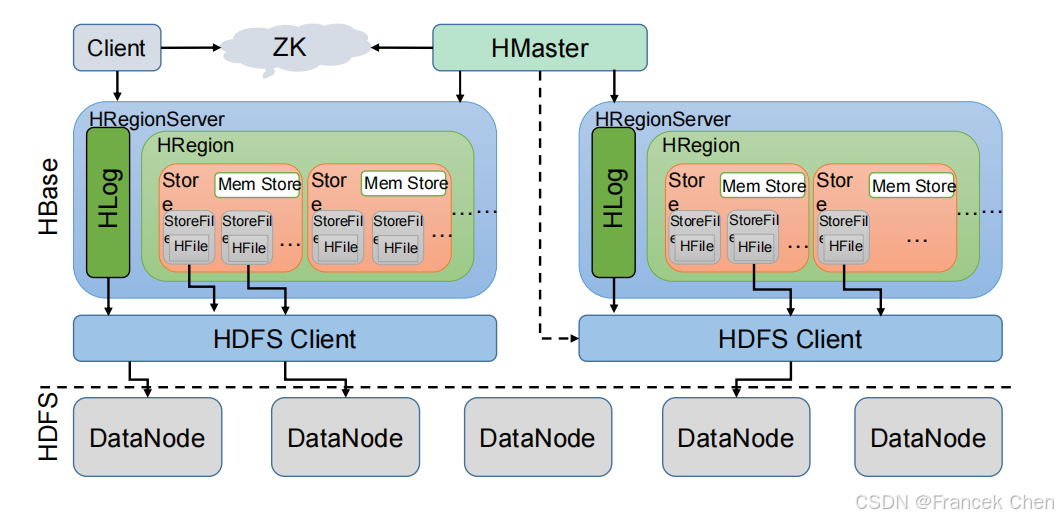
图3 HBase架构原理
三、MapReduce
Hadoop MapReduce 是针对谷歌 MapReduce 的开源实现。MapReduce 是一种编程模型,用于大规模数据集(大于 1 TB)的并行运算,它将复杂的、运行于大规模集群上的并行计算过程高度地抽象为两个函数—Map 和 Reduce,并且允许用户在不了解分布式系统底层细节的情况下开发并行应用程序,并将其运行于廉价的计算机集群上,完成海量数据的处理。通俗地说,MapReduce 的核心思想就是“分而治之”,它把输入的数据集切分为若干独立的数据块,分发给一个主节点管理下的各个分节点来共同并行完成;最后,通过整合各个节点的中间结果得到最终结果。
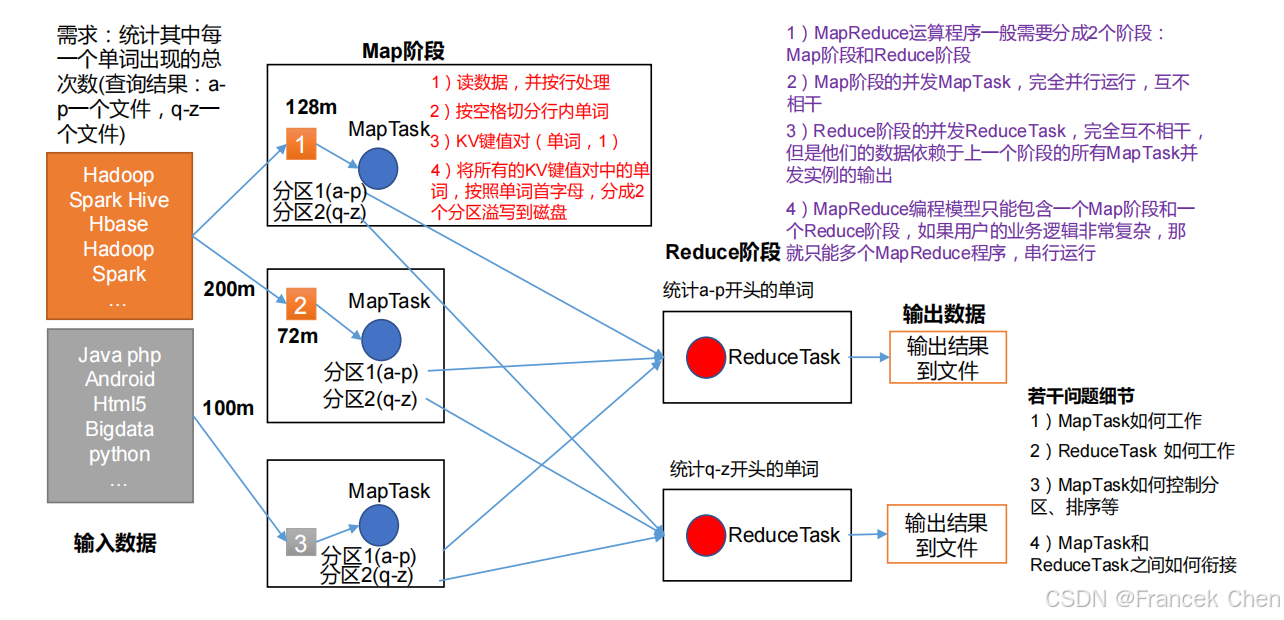
图4 MapReduce架构原理
四、Hive
Hive 是一个基于 Hadoop 的数据仓库工具,可以用于对 Hadoop 文件中的数据集进行数据整理、特殊查询和分析存储。Hive 的学习门槛较低,因为它提供了类似于关系数据库 SQL 的查询语言—HiveQL,可以通过 HiveQL 语句快速实现简单的 MapReduce 任务,Hive 自身可以将 HiveQL 语句转换为 MapReduce 任务运行,而不必开发专门的 MapReduce 应用,因而十分适合数据仓库的统计分析。
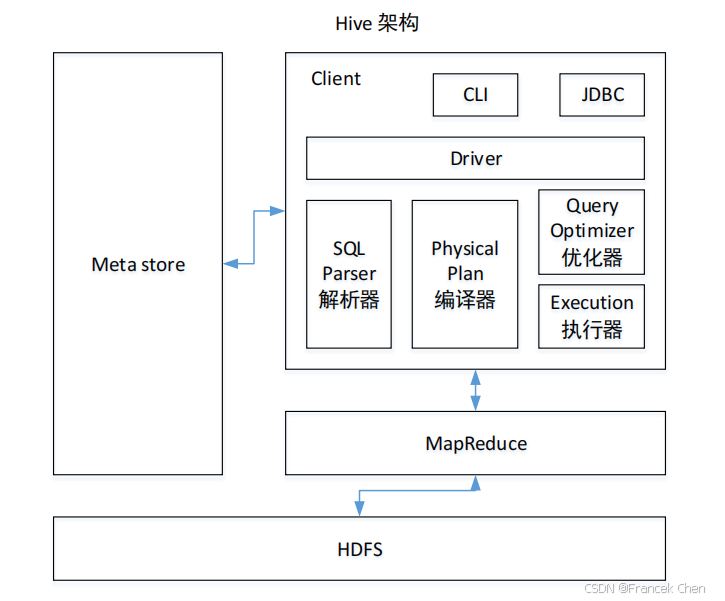
图5 Hive架构原理
五、Pig
Pig 是一种数据流语言和运行环境,适合于使用 Hadoop 和 MapReduce 平台来查询大型半结构化数据集。虽然编写 MapReduce 应用程序不是十分复杂,但毕竟也是需要一定的开发经验的。Pig 的出现大大简化了 Hadoop 常见的工作任务,它在 MapReduce 的基础上创建了更简单抽象的过程语言,为 Hadoop 应用程序提供了一种更加接近结构查询语言的接口。Pig 是一种相对简单的语言,它可以执行语句,因此当我们需要从大型数据集中搜索满足某个给定搜索条件的记录时,采用 Pig 要比 MapReduce 具有明显的优势,前者只需要编写一个简单的脚本在集群中自动并行处理与分发,后者则需要编写一个单独的 MapReduce 应用程序。
六、Mahout
Mahout 是 Apache 软件基金会旗下的一个开源项目,提供一些可扩展的机器学习领域经典算法的实现,旨在帮助开发人员更加方便快捷地创建智能应用程序。Mahout 包含许多实现,如聚类、分类、推荐过滤、频繁子项挖掘等。此外,通过使用 Apache Hadoop 库,Mahout 可以有效地扩展到云中。
七、ZooKeeper
ZooKeeper 是针对谷歌 Chubby 的一个开源实现,是高效和可靠的协同工作系统,提供分布式锁之类的基本服务(如统一命名服务、状态同步服务、集群管理、分布式应用配置项的管理等),用于构建分布式应用,减轻分布式应用程序所承担的协调任务。ZooKeeper 使用 Java 编写,很容易编程接入,它使用了一个和文件树结构相似的数据模型,可以使用 Java 或者 C 来进行编程接入。
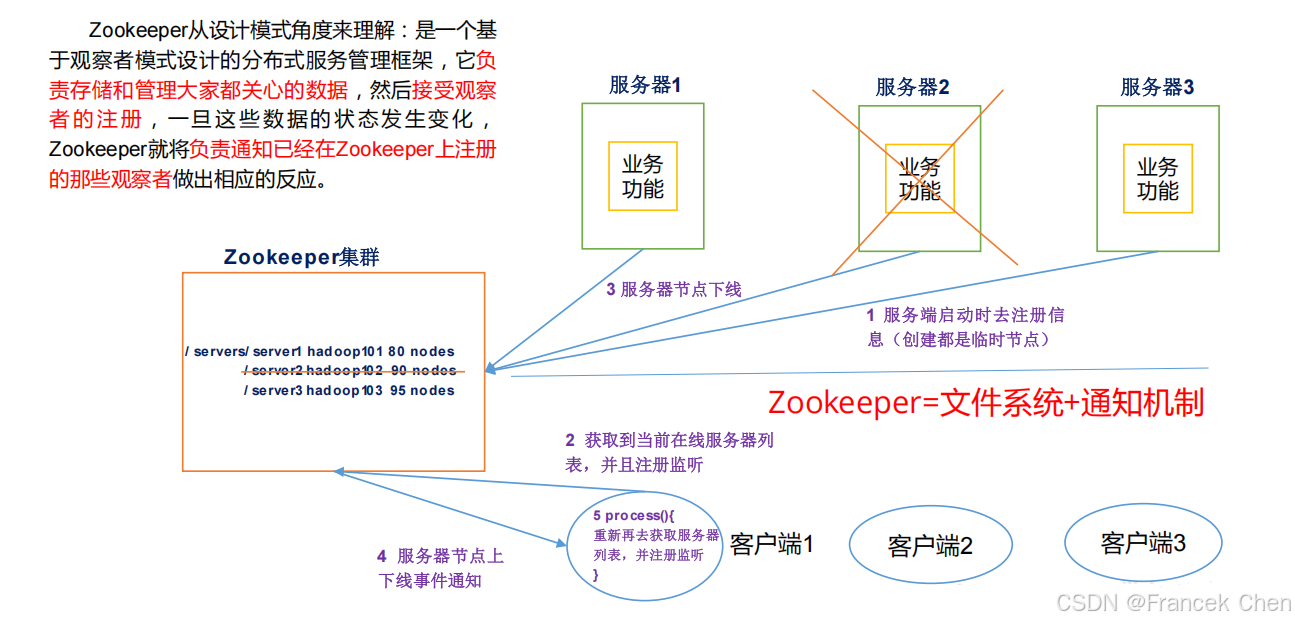
图6 ZooKeeper架构原理
八、Flume
Flume 是 Cloudera 提供的一个高可用的、高可靠的、分布式的海量日志采集、聚合和传输的系统。Flume 支持在日志系统中定制各类数据发送方,用于收集数据;同时,Flume 提供对数据进行简单处理并写到各种数据接收方的能力。
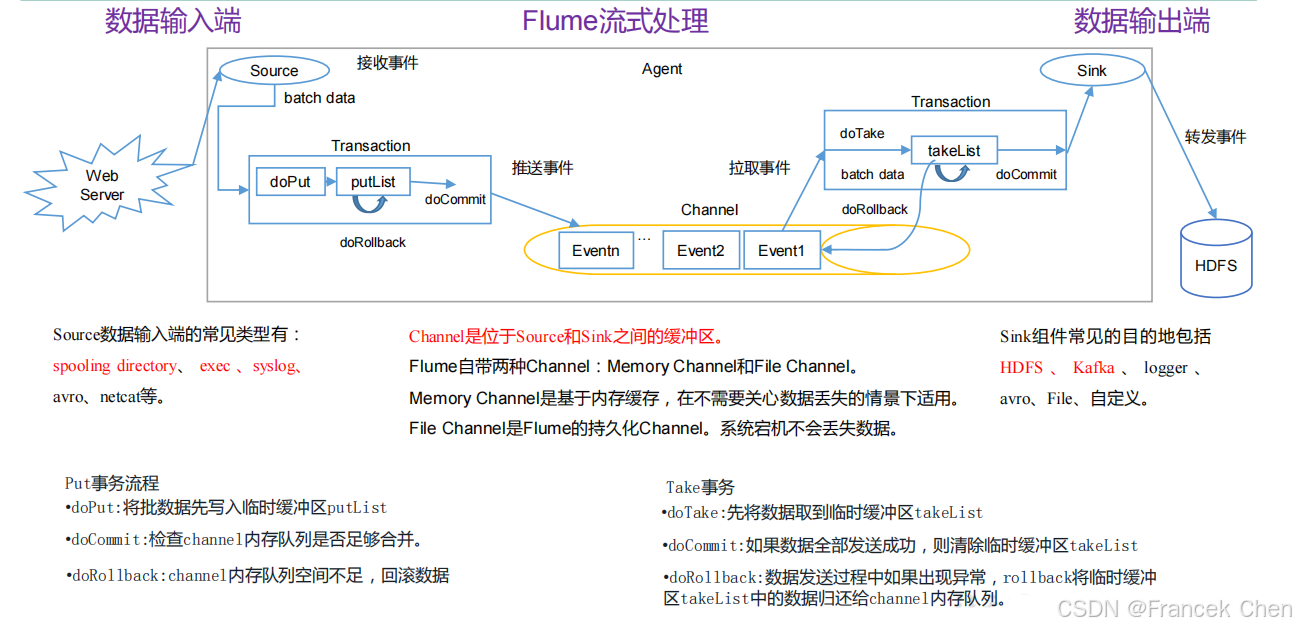
图7 Flume架构原理
九、Sqoop
Sqoop 是 SQL-to-Hadoop 的缩写,主要用来在 Hadoop 和关系数据库之间交换数据,可以改进数据的互操作性。通过 Sqoop 可以方便地将数据从 MySQL、Oracle、PostgreSQL 等关系数据库中导入 Hadoop(可以导入 HDFS、HBase 或 Hive),或者将数据从 Hadoop 导出到关系数据库,使传统关系数据库和 Hadoop 之间的数据迁移变得非常方便。Sqoop 主要通过 Java 数据库连接(Java DataBase Connectivity,JDBC)和关系数据库进行交互,理论上,支持 JDBC 的关系数据库都可以使 Sqoop 和 Hadoop 进行数据交互。Sqoop 是专门为大数据集设计的,支持增量更新,可以将新记录添加到最近一次导出的数据源上,或者指定上次修改的时间戳。
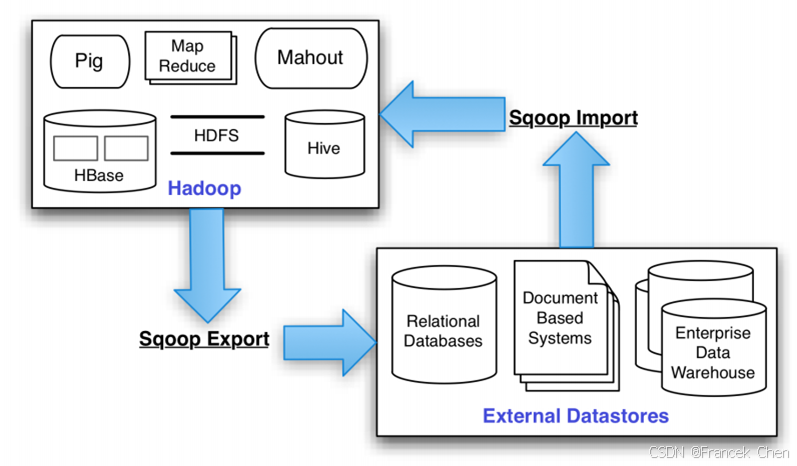
图8 Sqoop架构原理
十、Ambari
Apache Ambari 是一种基于 Web 的工具,支持 Apache Hadoop 集群的安装、部署、配置和管理。Ambari 目前已支持大多数 Hadoop 组件,包括 HDFS、MapReduce、Hive、Pig、HBase、ZooKeeper、Sqoop 等。
小结
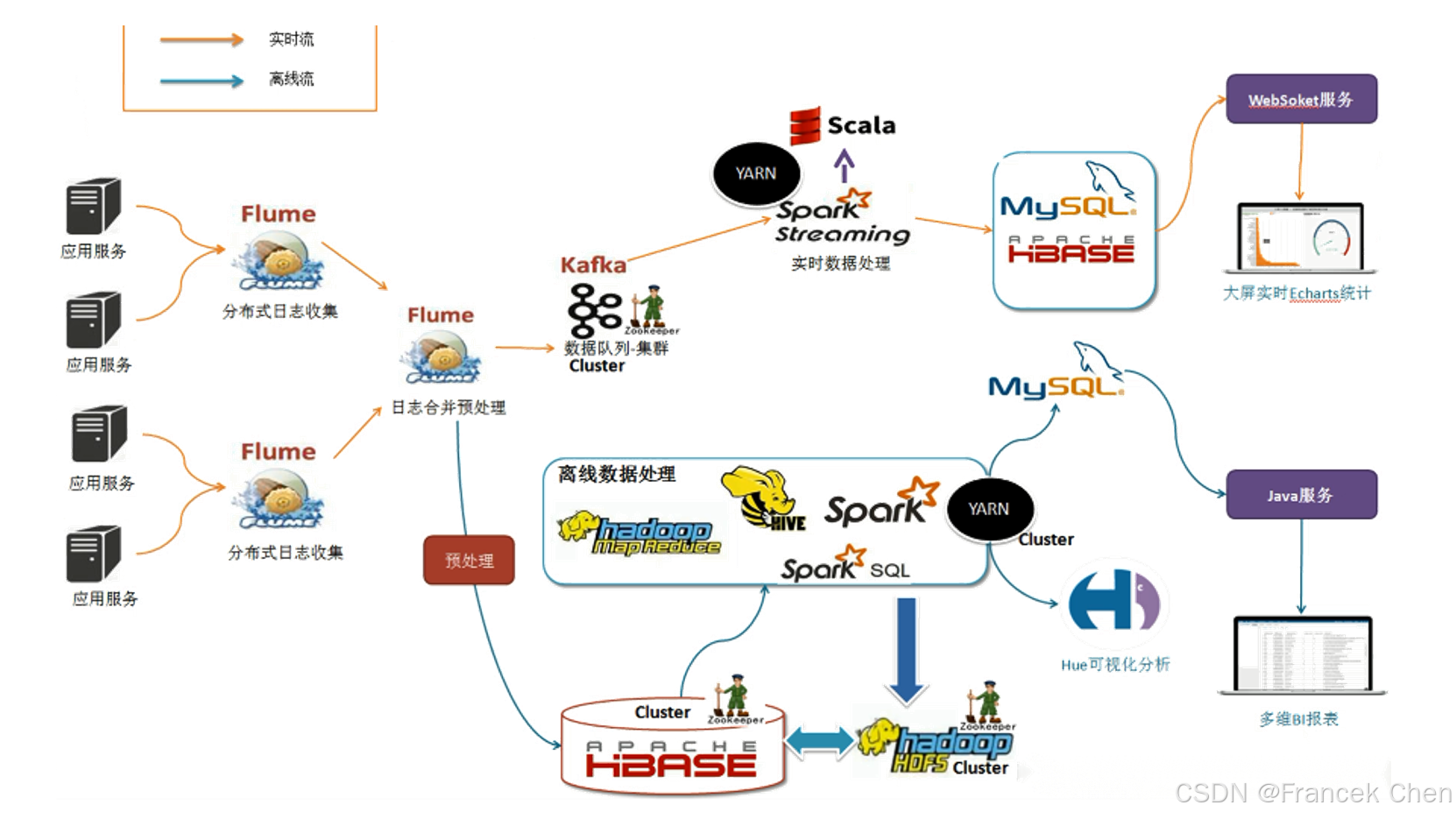
图9 Hadoop项目结构
Hadoop生态系统经过多年发展已相当成熟与完善,其包含众多功能组件。HDFS提供高容错的数据存储,HBase实现高效实时读写存储,MapReduce助力海量数据并行处理。Hive与Pig简化数据处理分析,Mahout提供机器学习算法支持。ZooKeeper保障分布式协同,Flume、Sqoop解决数据采集传输与交换问题,Ambari便于集群管理。这些组件相互协作,共同为大数据的存储、处理、分析等提供全面解决方案,推动大数据技术不断发展与应用。
欢迎 点赞👍 | 收藏⭐ | 评论✍ | 关注🤗
© 版权声明
文章版权归作者所有,未经允许请勿转载。


