【IoTDB】从 TsFile 到 AI 原生:揭秘 Apache IoTDB 高性能存储引擎 Apache IoTDB是清华主导的顶级时序数据库,专为工业物联网设计。创新树形模型映射物理层级,端边云协同架构大幅降本增效。相比InfluxDB,具备超高写入吞吐与压缩比,支持AI原生,是智能制造数... AI 2个月前340
Java高性能Socket编程实战 理解 Socket 内核机制是基础,结合 Java NIO/Netty 的异步非阻塞模型,配合参数调优与监控,可实现百万级并发的高性能网络服务。 国内服务器 2个月前260
使用飞算JavaAI实现在线图书借阅平台 本文通过使用飞算JavaAI开发在线图书借阅平台的实践,详细记录了从需求分析到代码生成的全流程,并转换为SpringBoot项目的过程。文章对比了飞算JavaAI与传统开发及同类产品的差异,指出其在开... AI 2个月前290
【大数据基础】大数据处理架构Hadoop:03 Hadoop的安装与使用 本文讲解在Ubuntu Kylin 16.04 LTS下Hadoop安装配置流程,涵盖安装系统与软件、创建用户、配置SSH、安装Java,以及单机和伪分布式安装与测试等关键步骤。 国内服务器 2个月前250
Spring Boot 全局异常处理策略设计(二):DispatcherServlet 与异常解析责任链源码解析 摘要:本文深入解析Spring Boot全局异常处理机制,重点剖析DispatcherServlet的核心作用及其异常处理流程。文章揭示了异常处理的责任链模式,详细介绍了HandlerExceptio... 国内服务器 2个月前220
HarmonyOS 应用开发环境搭建与 DevEco Studio 配置 刚开始接触 HarmonyOS 应用开发时,很多人会卡在环境搭建这一步:SDK 下载慢、模拟器启动失败、真机调试连不上等等。这些问题其实都有对应的解决方案,只是官方文档比较分散,新手容易踩坑。 国内服务器 2个月前210
【Hadoop+Spark+python毕设】咖啡店销售数据分析系统、计算机毕业设计、包括数据爬取、数据分析、数据可视化、实战教学 【Hadoop+Spark+python毕设】咖啡店销售数据分析系统、计算机毕业设计、包括数据爬取、数据分析、数据可视化、实战教学 国内服务器 2个月前280
如何把豆包的回答导出文件 摘要: AI助手豆包的高效响应常面临内容导出难题——截图不可检索,复制粘贴易丢失格式,手动整理耗时。针对这一痛点,DS随心转插件提供了轻量解决方案:支持一键导出豆包回答为PDF、Word等格式,保留代... 国内服务器 2个月前340
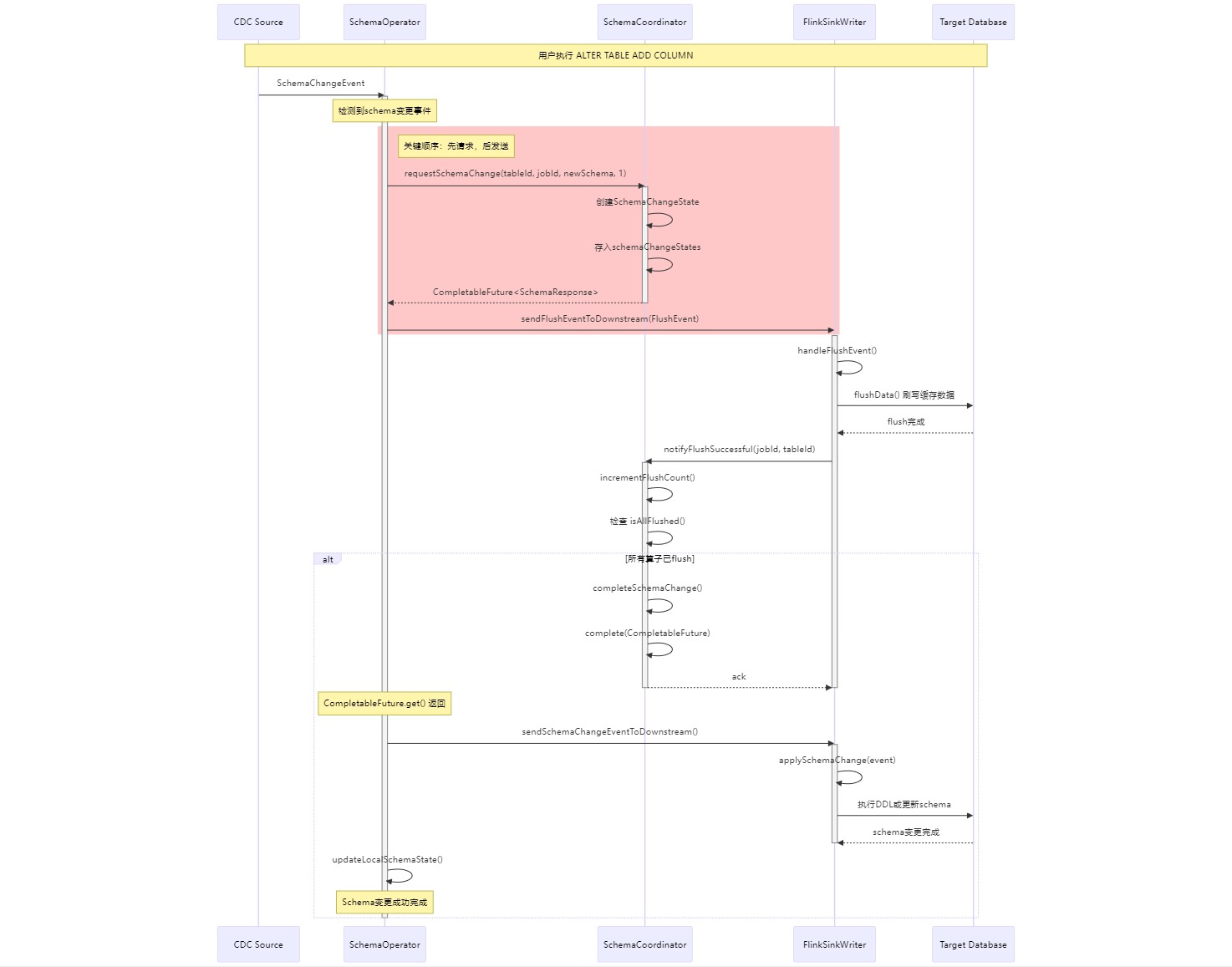
巾帼力量助力 Flink 引擎 CDC 源模式演进支持 | Apache SeaTunnel 开源之夏成果 这样确保 SchemaCoordinator 先创建好 schema change state,之后请求的时候就不会返回空,然后算子将 FlushEvent 被发送到下游,下游处理完 FlushE... 国内服务器 2个月前260
spark、mapreduce、flink核心区别及浅意理解 主流分布式数据处理框架对比:MapReduce、Spark和Flink分别代表批处理、内存计算和流批一体三个技术时代。MapReduce适合超大规模离线处理但延迟高;Spark在批处理和准实时场景表现... 国内服务器 2个月前280