3分钟掌握Vue虚拟滚动列表:告别大数据渲染卡顿的终极方案 在当今数据驱动的应用开发中,处理海量列表数据已成为前端开发者的日常挑战。当面对成千上万条数据需要渲染时,传统列表组件的性能瓶颈暴露无遗,页面卡顿、内存溢出等问题频发。而vue-virtual-scro... 国内服务器 3个月前320
计算机大数据毕业设计hadoop+spark+hive电商数据分析大屏可视化推荐系统 大数据毕业设计(源码+LW+PPT+讲解) 本文介绍了基于Hadoop+Spark+Hive的电商数据分析大屏可视化推荐系统。系统整合用户行为、商品和供应链等多源数据,通过混合推荐算法(协同过滤+内容推荐+图神经网络)提升推荐准确率,并实现实时... 国内服务器 2个月前290
大数据新视界 — Impala 性能优化:分布式环境中的优化新视野(下)(28 / 30) 本文聚焦分布式环境下 Impala 性能优化。深入剖析数据传输开销与节点资源竞争对查询性能影响,详述数据布局优化(分区策略、数据本地化)与资源管理优化(动态资源分配、查询队列管理)策略,并以互联网金融... 国内服务器 3个月前270
三、Spark 运行环境部署:全面掌握四种核心模式 部署Spark就像选择不同的道路,从用于学习的Local“院子”,到独立的Standalone“专线”,再到与Hadoop集成的YARN“高速网”,而Windows本地开发则需先搞定特殊的winuti... 国内服务器 3个月前260
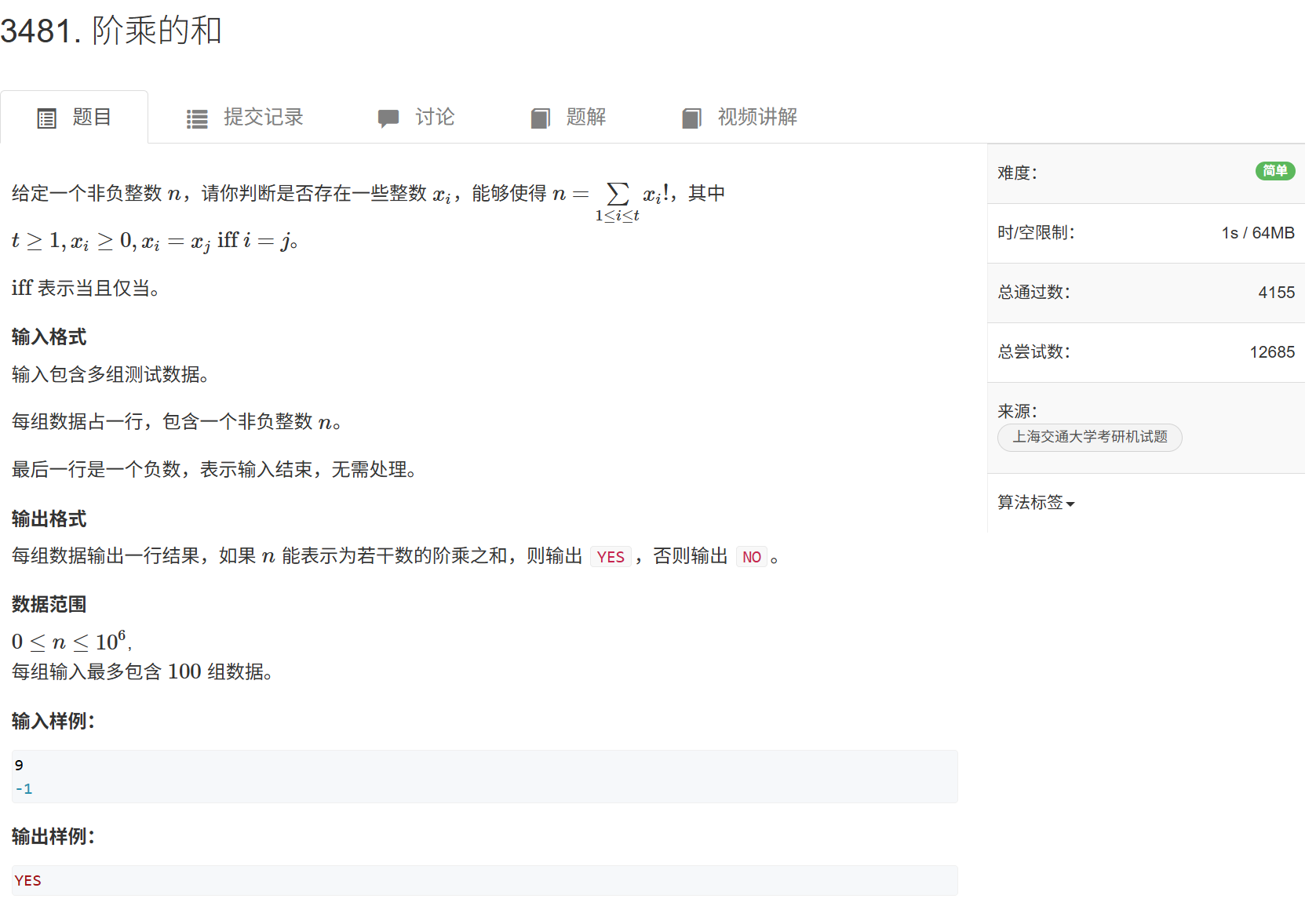
3481.阶乘的和 1、先初始化一个set(作用是使阶乘之和不重复),初始数据是{0}(0的作用是计算1!所以考虑一个数能否由几个数的阶乘组成,我们可以先计算所有可能的阶乘之和,用空间换时间。4、由于题目要求至少有一个数... 国内服务器 2个月前260
【TextIn大模型加速器 + 火山引擎】用Coze+TextIn+飞书搭建智能合同审查工作流 合同审查AI工作流通过TextIn+Coze+飞书技术栈实现法务自动化。该方案利用TextIn的高精度文档解析能力(支持PDF/图片等10+格式,95%准确率),结合Coze低代码平台搭建智能审查流程... AI 2个月前360
宽依赖的代价:Spark 与 MapReduce Shuffle 的数据重分布对比 摘要 Shuffle是大数据处理中的核心环节,负责数据重分区和跨节点传输。本文对比分析了Hadoop MapReduce和Spark的Shuffle机制:MapReduce采用基于磁盘的排序Shuff... 国内服务器 3个月前390
基于大数据的短视频用户兴趣分析-hive+django+spider 摘要:本系统基于Django框架开发,采用Python3.8和MySQL5.7数据库,构建了一个短视频用户兴趣分析平台。系统利用Hadoop处理海量数据,通过随机森林回归算法预测用户兴趣,并使用ECh... 国内服务器 3个月前280
大数据领域 Hadoop 与 NoSQL 数据库的协同应用 随着互联网、物联网的发展,企业每天产生的日志、用户行为、设备数据等呈指数级增长(据IDC预测,2025年全球数据量将达175ZB)。存储能力有限:无法弹性扩展存储TB级甚至PB级数据;计算效率低:复杂... 国内服务器 2个月前290