爆火Browser-Use实战:让AI替你操作浏览器,爬虫/自动化填表一行代码搞定 还在为写爬虫抠破脑袋、为重复填表熬到半夜?2026年最新爆火的直接把浏览器自动化卷到新高度,AI驱动+一行代码,不管是数据爬取、自动填表还是网页操作,零基础也能秒上手,星标7.6万+可不是吹的😎对比S... AI# Langchain 1个月前190
Flink 内部通信机制:注册、心跳与任务协作 Flink控制面通信基于Pekko RPC框架实现,核心组件包括JobMaster、ResourceManager和TaskManager。RPC抽象层与Pekko通信层采用分层设计,确保组件间高效交... 国内服务器 1个月前170
88万个AI代理在一起泡论坛。内容让我看得毛骨悚然。AI代理数量还在以10分钟10万在增加。 毕竟一个拥有无限知识和精力的人,生活在狼群,是无法成为真正的人类的。这个完全由AI助理参与,人类无法参与的论坛,异常的火爆。10分钟不到,我写好了这篇文章的标题后,参与的AI助理数量已经从88万增加到... AI 1个月前200
【用户行为归因分析项目】- 【企业级项目开发第五站】数据采集并加载到hive表 本文介绍了基于Spark的数据处理系统实现,主要包含三个核心模块:1)主程序PreRowDataToOdsHive负责初始化Spark环境并调用数据加载方法;2)核心服务类LoadRowToOds实现... 国内服务器 1个月前190
windows Hive使用全攻略:从入门到实战,轻松搞定大数据处理 – Hadoop windows安装 本文介绍了Hive在大数据生态中的核心作用及其典型应用场景。Hive作为基于Hadoop的数据仓库工具,通过类SQL语言(HQL)降低大数据处理门槛,适用于数据仓库构建、海量数据分析、用户行为分析等场... 国内服务器 1个月前230
大数据领域 Hadoop 高可用方案的设计与实现 在大数据时代,数据量呈爆炸式增长,Hadoop 作为一款强大的分布式计算框架,被广泛应用于数据存储和处理。然而,Hadoop 集群中的单点故障可能会导致整个系统瘫痪,数据丢失或服务中断。因此,设计和实... 国内服务器 1个月前220
大数据新视界 — Hive 数据湖集成与数据治理(下)(26 / 30) 本文深入探讨 Hive 在数据湖中的集成与数据治理,解析集成方式、治理流程与实践案例,提供数据湖管理的全面指南,助力企业构建高效数据湖体系。 国内服务器 1个月前250
计算机毕业设计Hadoop+Spark+Hive招聘推荐系统 招聘大数据分析 大数据毕业设计(源码+文档+PPT+ 讲解) 本文提出了一种基于Hadoop+Spark+Hive的分布式招聘推荐系统架构,解决了传统系统面临的数据规模受限、推荐精度低和实时性不足等问题。系统采用分层设计,通过HDFS存储海量数据,Spark优化... 国内服务器 1个月前240
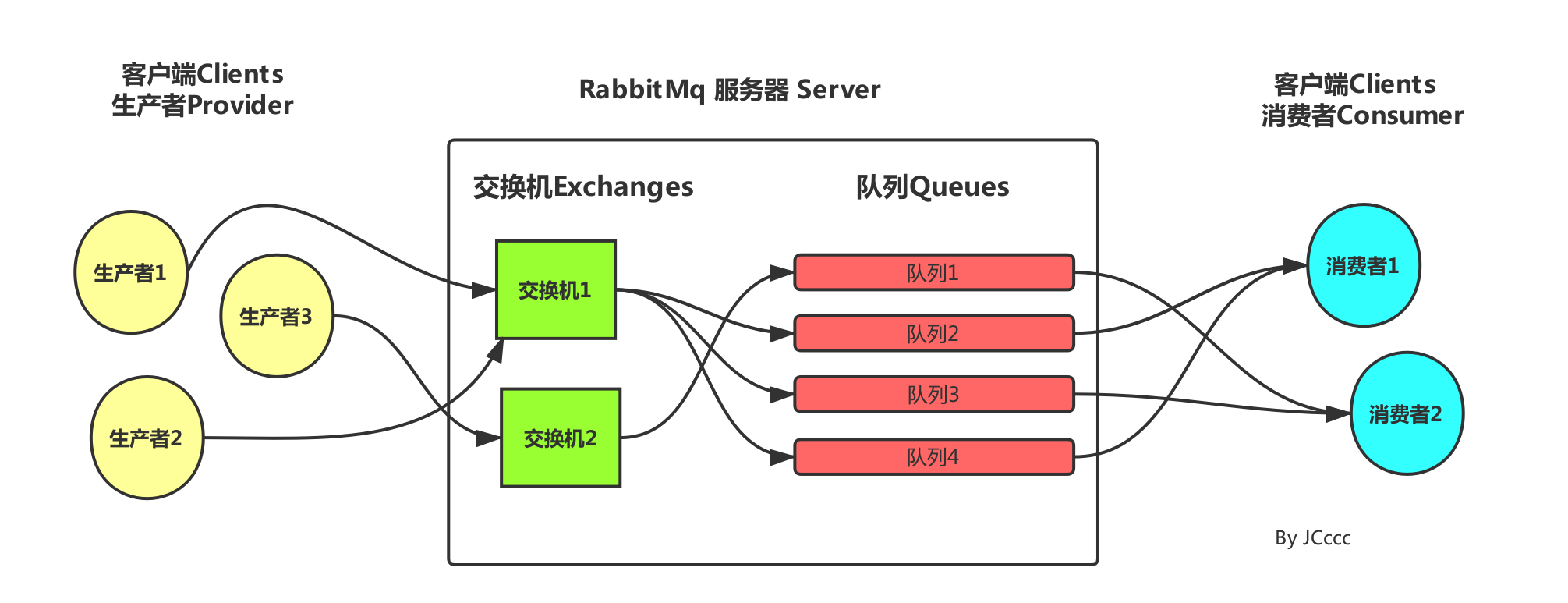
RabbitMQ之交换机 在讲交换机之前我们需要了解一些概念,在RabbitMQ工作流程有一项叫Exchange(交换机:消息的分发中心****),它的作用是将生产者发送的消息转发到具体的队列,队列再将消息以推送或者拉取方式给... 国内服务器 1个月前210