WeArchive | 公众号文章保存工具 点击顶部导航栏的"设置"按钮可以配置以下选项:默认导出格式PDF页面大小和边距Word样式模板图片处理方式下载文件保存路径自动清理临时文件周期点击"保存设置"按... 国内服务器 4个月前800
大数据新视界 — Hive 集群搭建与配置的最佳实践(2 – 16 – 13) 本文围绕 Hive 集群搭建与配置,详述硬件选型、软件安装、配置优化、数据布局及高可用性等方面,含丰富案例与代码,具实用价值。 国内服务器 4个月前360
解决 RabbitMQ 的可靠性投递与消息重复消费问题思路 本文介绍了如何确保消息队列(MQ)在分布式系统中的可靠投递和防止重复消费。首先阐述了消息传递的四个关键阶段:生产者到交换机、交换机到队列、RabbitMQ存储、队列到消费者,并分别给出了Confirm... 国内服务器 4个月前360
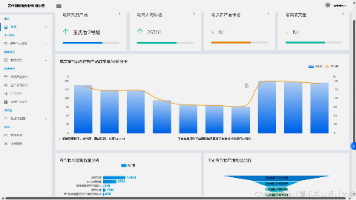
基于 Hadoop MapReduce + Spring Boot + Vue 3 的每日饮水数据分析平台 本文介绍了一个基于Hadoop MapReduce、Spring Boot和Vue 3的每日饮水数据分析平台。该平台采用前后端分离架构,实现了从数据采集、MapReduce分析处理到可视化展示的完整流... 国内服务器 4个月前420
基于深度学习的大数据时序预测模型构建指南 你是否遇到过这些场景?奶茶店老板需要预测明天的销量,避免原料浪费;电厂需要预测未来3天的用电负荷,调整发电计划;股民想根据历史股价预测下周走势……这些都属于时序预测(Time Series Forec... 国内服务器 4个月前390
HiveSQL 语法详解与常用 SQL 写法实战 用于创建、修改和删除数据库和表。HiveSQL 凭借其类 SQL 的语法、强大的批处理能力和与 Hadoop 生态的深度集成,成为大数据离线分析的主流工具之一。掌握其核心语法和常用写法,不仅能高效完成... 国内服务器 4个月前380
大数据分布式计算中的序列化优化 在分布式计算框架(如Apache Spark、Flink、Hadoop)中,数据需要在Worker节点、TaskExecutor、存储系统(如HDFS、Kafka)之间频繁传输。序列化性能直接影响系统... 国内服务器 4个月前520
计算机毕业设计Spark+Hadoop+Hive+LLM大模型+Django农产品价格预测系统 农产品销量预测 农产品推荐系统 智慧农业 本文介绍了一个基于Spark+Hadoop+Hive+LLM大模型+Django的农产品价格预测系统。系统通过整合多源数据(价格、天气、舆情等),采用五层分布式架构实现数据采集、存储、计算、预测与服务... 国内服务器 4个月前380
PyTorch-CUDA-v2.6镜像是否支持Kafka流式数据处理? PyTorch-CUDA官方镜像专注GPU计算,不预装Kafka等通信组件。要在流式AI系统中接入Kafka,应基于原镜像构建定制子镜像,按需添加客户端依赖。这种分层设计保障了环境稳定与职责解耦,符合... 国内服务器 4个月前390