电影推荐系统 | Python Django框架 双数据库 协同过滤 requests bootstrap3 大数据 毕业设计源码 文章摘要: 本项目开发了一个基于Python+Django的电影推荐系统,采用协同过滤算法实现个性化推荐。系统包含数据采集(爬取豆瓣3000条电影数据)、电影展示(多维度分类与搜索)、用户交互(登录... 国内服务器 4个月前540
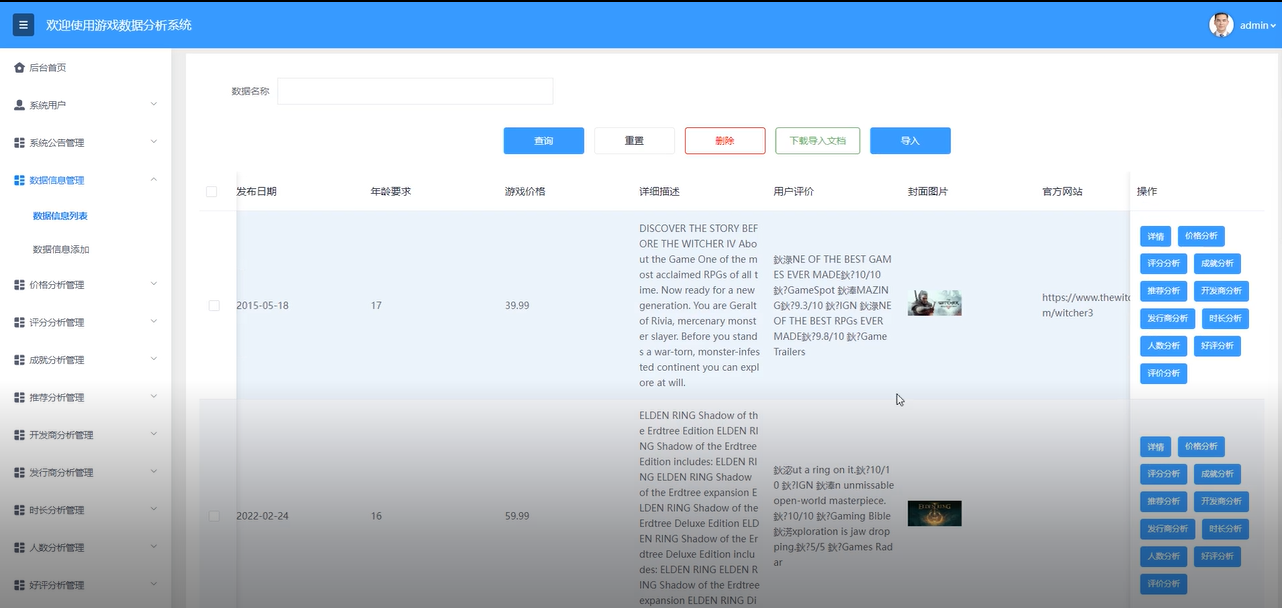
基于Hadoop的游戏数据分析系统—免费毕设源码分享63632 随着大数据技术的迅速发展,游戏产业迎来了前所未有的数据爆炸,如何高效地分析和利用这些数据成为关键问题。本文提出了一种基于Hadoop的游戏数据分析系统,利用HDFS进行海量数据的分布式存储,结合Had... 国内服务器 4个月前690
气象数据分析与可视化系统:基于Spark的大数据处理方案(中科院计算机研究生) 本文介绍了一个基于Spark和Python的气象数据分析项目,专注于高效处理大规模气象数据并生成可视化图表。项目采用双版本实现(Spark+Pandas),严格遵循气象观测标准计算日平均气温,处理57... 国内服务器 4个月前470
Spark-TTS语音合成:新手10分钟从零到精通实战指南 作为一款强大的开源语音合成工具,Spark-TTS语音合成系统在实际使用中可能会遇到各种技术障碍。本文专为新手用户设计,通过"问题发现→快速解决→深度优化"的三段式结构,帮助你快速... 国内服务器 4个月前360
DataInLong任务切换实践:从Kafka-A到Kafka-B的数据迁移指南 本文详细介绍了如何将DataInLong任务从Kafka-A迁移到Kafka-B,同时保持目标表DLC-A不变。首先,停止当前任务并验证其完全停止;其次,修改任务配置,将数据源从Kafka-A切换为K... 国内服务器 4个月前390
python从入门到精通:pyspark实战分析 spark:Apache Spark是用于大规模数据(large-scala data)处理的统一(unified)分析引擎。简单来说,Spark是一款分布式的计算框架,用于调度成本上千的服务器集群... 国内服务器 4个月前450
SparkMD5终极指南:前端大文件校验的快速解决方案 [特殊字符] 在现代前端开发中,处理大文件校验是一个常见但具有挑战性的任务。SparkMD5作为一款轻量级的JavaScript MD5实现,提供了闪电般的计算速度和增量式处理能力,成为前端文件校验的终极解决方案... 国内服务器 4个月前360
【实时数据处理新范式】:Kafka Streams与反应式编程的完美融合 掌握实时数据处理新范式,Kafka Streams 反应式编程集成让流数据响应更高效。适用于高并发、低延迟场景,结合背压控制与事件驱动架构,提升系统弹性与可维护性。开发响应式流应用从此更简单,值得收藏... 国内服务器 4个月前420
【数据库】时序数据库选型指南:从大数据角度解析IoTDB的优势 时序数据库选型不是单纯的技术比较,而是需要综合考虑业务场景、团队能力、成本预算、生态依赖等多维度的系统工程。Apache IoTDB自2018年开源以来,已在国家电网、中冶赛迪、华为云、阿里巴巴等数千... 国内服务器 4个月前640