大数据场景时序数据库选型指南——Apache IoTDB实践与解析 本文探讨了大数据场景下时序数据库选型的关键维度,重点推荐了Apache IoTDB作为优选方案。文章从性能、生态兼容性、易用性、成本可控性和可扩展性五个核心维度分析了时序数据库选型标准。IoTDB凭借... 国内服务器 4个月前410
Sarama:Go语言Kafka客户端完整指南 想象一下,当你需要在Go应用中集成Kafka消息队列时,面对复杂的协议细节和性能优化挑战,是否曾感到无从下手?Sarama正是为解决这一痛点而生,它为Go开发者提供了一个功能完整、性能卓越的Kafka... 国内服务器 4个月前410
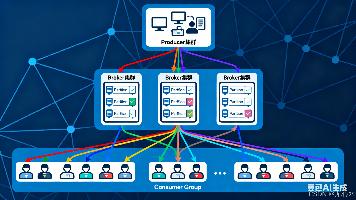
【分布式利器:Kafka】Kafka基本原理详解:架构、流转机制与高吞吐核心(附实战配置) Kafka是一个分布式流处理平台,以高吞吐、高可靠和高扩展性著称,广泛应用于日志收集、实时分析和数据同步场景。其核心架构包括生产者、消费者、Broker节点、Topic和Partition,通过分区并... 国内服务器 4个月前410
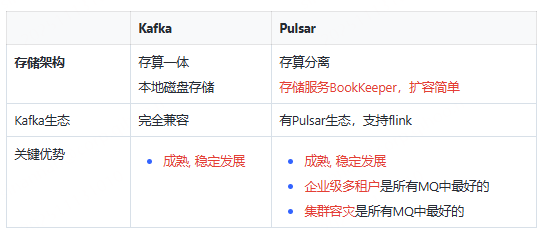
Kafka 消费积压影响写入?试试 Pulsar Pulsar 中 topic 消费积压不会导致写超时,Pulsar 读写磁盘分开,写数据使用WAL磁盘,顺序写,WAL的数据会在内存中赞批刷到Ledger磁盘,数据消费时,如果没命中缓存,从Ledge... 国内服务器 4个月前350
Sentinel – 使用 Apollo 或 ZooKeeper 存储规则:多注册中心适配 本文介绍了如何让Sentinel支持多种注册中心(如Apollo和ZooKeeper)来存储规则,提升微服务架构的灵活性。内容包括:1)多注册中心支持的必要性,满足不同技术栈需求;2)环境准备与Mav... 国内服务器 4个月前400
深入Spark核心:Shuffle全剖析与实战指南 在 Spark 的分布式计算体系里,Shuffle 被定义为数据重新分布的关键过程。当我们执行那些需要跨分区聚合数据的操作时,Shuffle 便会被触发。其核心任务是将上游 Stage 的输出数据,按... 国内服务器 4个月前440
【大数据分析毕设选题】基于Hadoop+Django天猫订单交易系统全解析 毕业设计 选题推荐 毕设选题 数据分析 机器学习 数据挖掘 这是一个基于Hadoop和Django的毕设项目,主要对天猫订单数据进行可视化分析。后端用Spark处理海量数据,前端用Echarts画出销售趋势、地域分布等图表,帮你把复杂的数据看得明明白白。 国内服务器 4个月前430
中小型企业大数据平台全栈搭建:Hive+HDFS+YARN+Hue+ZooKeeper+MySQL+Sqoop+Azkaban 保姆级配置指南 对于中小企业,构建一套完整的本地化大数据平台需兼顾成本、易用性和扩展性。本文基于生产环境实践,详细讲解以下组件的安装、配置与联动;提供全组件官方下载地址和 配置模板,助您快速搭建企业级数据平台 国内服务器 4个月前410
Hadoop 安装与搭建全流程教学【全网最全超详细保姆级教学】 本文是面向零基础读者的 Hadoop 3 节点集群保姆级安装教程,详细讲解基于 CentOS 7 系统从虚拟机创建、静态 IP 配置、JDK 与 Hadoop 安装,到 SSH 互信搭建、集群配置文件... 国内服务器 4个月前430
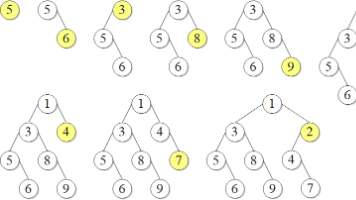
笛卡尔树简介 ← 基于单调栈创建 笛卡尔树(Cartesian Tree)是由一个序列 a[1], a[2], ..., a[n] 唯一确定的二叉树,其同时满足二叉查找树(BST)性质和堆性质。笛卡尔树的每个结点包含一对儿信息 (pr... 国内服务器 4个月前430