Python大数据可视化:基于大数据技术的共享单车数据分析与辅助管理系统_flask+hadoop+spider 在搭建过程中,最开始的工作是从查阅相关资料开始的,通过在互联网的共享单车数据分析与辅助管理系统资料查询和阅读,对整个共享单车数据分析与辅助管理系统有了整体的概念了解,然后对本共享单车数据分析与辅助管理... 国内服务器 3个月前230
【Kafka 进阶之路】详解 Kafka 副本机制 LEO (Log End Offset):副本本地日志最后一条消息的偏移量 + 1(下一条待写入位置)HW (High Watermark):所有 ISR 副本已同步完成的消息最大偏移量,消费者只能读... 国内服务器 1个月前220
90% 人答不好的 Zookeeper 权限机制,其实就这三点 面试官盯着我问:“你们线上 Zookeeper 是怎么做权限控制的?”那一刻,我脑子里闪过的不是代码,而是一栋写字楼的门禁系统。今天,我们就用“门禁故事”聊透 Zookeeper ACL 权限控制机制... 国内服务器 1个月前220
终极指南:如何使用Spark-TTS构建企业级语音合成系统 Spark-TTS是一款基于大型语言模型(LLM)的高效文本转语音系统,能够生成高度自然、准确的语音。它采用创新的单流解耦语音令牌技术,直接从LLM预测的代码中重建音频,无需额外的生成模型,为企业级应... 国内服务器 1个月前220
2026年(第19届)中国大学生计算机设计大赛大数据主题赛参赛指南——“健康数据洞察” 旨在鼓励参赛者探索智能体在健康数据分析中的创新应用,例如利用智能体进行自动化数据探索、关联模式发现、预测建模以及资源优化策略的模拟推演,以人机协作的方式深化对健康生态系统复杂性的理解,并生成更具洞察力... 国内服务器 1个月前220
Hadoop 经典案例:WordCount 原理 + 代码逐段解析 + 实操全流程 本文详解Hadoop生态经典案例WordCount,从原理拆解、代码解析到集群实操,完整演示MapReduce实现单词计数的流程,涵盖Map拆分、Shuffle分组、Reduce聚合的核心逻辑,提供H... 国内服务器 1个月前220
数据仓库实战:数据仓库与数据湖融合架构(湖仓一体)全解 ## 摘要 在现代大数据架构中,数据湖(Data Lake)和数据仓库(Data Warehouse)不再是二选一的关系,而是走向深度融合——即湖仓一体(Lakehouse)。本文将用最通俗、最体系化的方式,讲解... 国内服务器 1个月前220
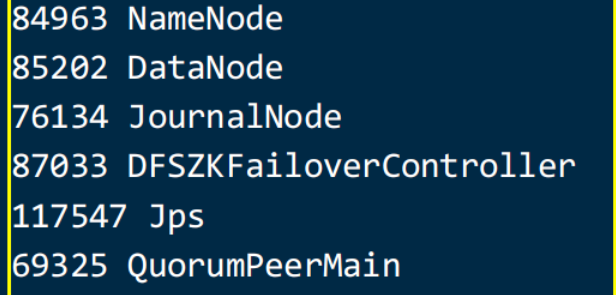
Hadoop高可用集群搭建全攻略 首先准备3台服务器 hadoop11 hadoop12 hadoop13完成分布式的搭建 hadoop11为namenode datanode hadoop12 hadoop13 为datanodej... 国内服务器 2个月前220
大数据领域数据安全的法规与合规要求 我是张三,一位拥有10年大数据安全经验的软件工程师,曾在某全球知名互联网公司负责数据安全合规工作,参与过多个大型大数据平台的安全体系建设。我擅长用通俗易懂的语言讲解复杂的技术概念,希望我的文章能帮你解... 国内服务器 2个月前220