基于python大数据机器学习旅游数据分析可视化推荐系统(完整系统+开发文档+部署教程+文档等资料) 本文介绍了一个基于Python的智慧旅游数据分析与推荐系统,该系统整合了机器学习TF-IDF算法、Requests爬虫、Echarts可视化、SnowNLP情感分析和Flask框架等技术。系统通过爬取... 国内服务器 2周前140
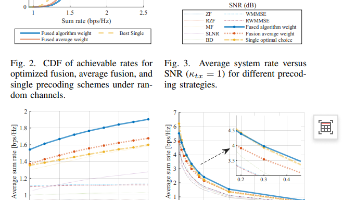
【mimo-硬件损伤-预编码】融合预编码与优化算法 —— 从“选最优”到“加权组合”及仿真验证 平均工作点(Average Operating Point)定义为所有基预编码器等权重融合Vikavg1B∑b1BVikbVikavgB1b1∑BVikb也就是说,在平均工作点,α1B1B1B... 国内服务器 2周前140
谢飞机面Java大厂:音视频场景下的Spring Boot + Kafka + Redis实战三连问 以幽默面试故事形式,带小白掌握音视频场景中Spring Boot集成Kafka消息队列与Redis缓存的典型架构设计、技术选型依据及避坑要点。含3轮递进式真题+逐题深度解析。 国内服务器 2周前130
算法构建人【上】大数据定义你是谁 最后看到的不是真实世界,偏见的复刻,不幸的、炫耀的情绪激化,日常陷入无尽的情绪流中做自我斗争。越刷越同质、越看越单一。当下媒介彻底过载,海量资讯铺满屏幕,算法在用信息批量塑造和规训,不停的检测打标看你... 国内服务器 2周前120
Sqoop导入数据到HBase完全指南:原理、流程与实战 需求说明实时查询HBase支持毫秒级的随机读写,适合在线业务海量存储基于HDFS,可扩展到PB级别稀疏数据HBase可以高效处理大量列为空的稀疏数据版本管理HBase支持多版本数据存储,可追溯历史变化... 国内服务器 2周前110
3、Spark 函数_d/e/f/j/h/i/j/k/l 本文介绍了Apache Spark SQL中常用的日期处理函数,包括date()、date_add()、date_diff()、date_format()等。这些函数可用于日期转换、日期加减、日期差计... 国内服务器 2周前160
Hadoop2 – MapReduce详解 (1)是什么序列化就是把内存中的对象,转换成字节序列(或其他数据传输协议)以便于存储(持久化)和网络传输。反序列化就是将收到字节序列(或其他数据传输协议)或者是硬盘的持久化数据,转换成内存中的对象... 国内服务器 2周前140
【赫兹威客】完全分布式HBase测试教程 本文详细介绍了在3台虚拟机(hadoop01~hadoop03)组成的完全分布式环境中进行HBase组件独立测试的全流程。测试内容包括环境准备、服务启停、Web页面验证和表操作命令验证等核心功能。文档... 国内服务器 2周前150