实时数据处理架构:从 Kafka 到 Flink 实时数据处理是指对数据进行低延迟、高吞吐的处理,通常在毫秒到秒级完成数据的采集、处理和分析。实时数据处理架构是现代数据系统的重要组成部分,它能够帮助企业实时洞察业务状况,做出快速决策。从 Kafka ... 国内服务器 2个月前180
Hadoop数据分片策略深度解析:从原理到自定义实现 引言:分片——分布式计算的起点一、数据分片的核心概念1.1 分片(Split)与块(Block)的区别1.2 分片大小的计算逻辑1.3 调整分片大小的方式**使分片小于块大小****使分片大于块大小... 国内服务器 3个月前180
中小企业AI接入的合规效率方案:轻量接入层的数据治理与多模型路由 中小企业AI接入的痛点,不是缺一个完美的企业级平台,而是在资源有限的情况下,快速获得治理能力。本周部署,不是半年后按需启用,不是过度工程成本可见,不是月底黑洞模型自由,不是绑定一家关于AllToken... 国内服务器 4周前170
人工智能与大数据专业毕业设计选题合集与优选 稳妥题目推荐(保命帖) 人工智能与大数据专业毕业设计的主流方向与技术路径,覆盖数据分析、数据可视化、机器学习、深度学习、自然语言处理、推荐系统、实时大数据处理、计算机视觉、强化学习、数据安全核心领域。该选题适合计算机科学与技... 国内服务器 4周前170
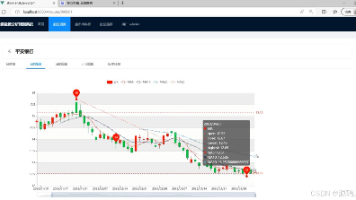
计算机毕业设计:Python股票数据分析与ARIMA预测系统 Flask框架 ARIMA 数据分析 可视化 大数据 大模型(建议收藏)✅ 本文介绍了一个基于Python开发的股票数据分析预测系统。系统采用Flask+Vue技术架构,通过IG507金融数据接口获取实时行情,运用ARIMA算法进行股价预测。主要功能包括:多周期K线图展示(分... 国内服务器 4周前170
Hadoop MapReduce 详解 MapReduce是一种分布式计算框架,通过"分而治之"的思想将大数据处理任务分解为Map(并行处理)和Reduce(汇总结果)两个阶段。它通过将计算任务分配给集群... 国内服务器 1个月前170
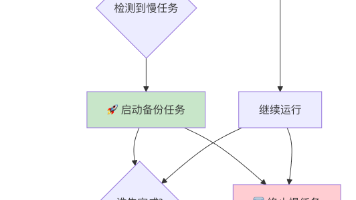
【西瓜带你学Kafka | 第五期】Kafka 副本同步机制与集群健康管理:ISR、故障选举与关键配置(文含图解) 本文围绕 Kafka 副本同步与集群管理展开,详解 AR、ISR、OSR 三组副本的概念与动态流转机制,分析副本被踢出 ISR 的条件与 Leader 宕机时的选举策略,讲解 Broker 有效性的判... 国内服务器 1个月前170
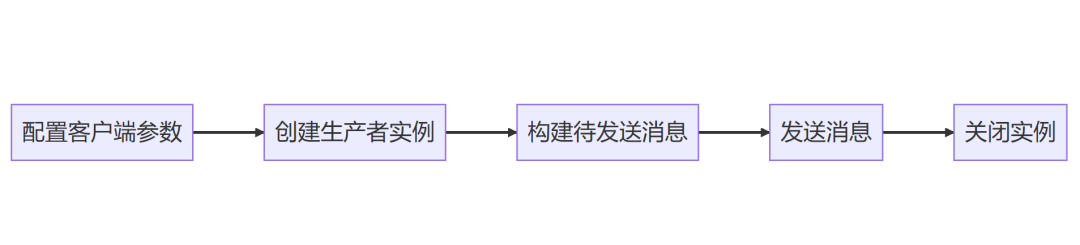
C++如何实现Kafka生产者客户端?10 分钟构建第一个应用 Kafka 集群的连接地址,生产者通过这些地址发现 Kafka 集群。可以配置多个地址,以提高可用性。: 将消息的 Key 序列化成字节数组的类。: 将消息的 Value 序列化成字节数组的类。ack... 国内服务器 1个月前170
Kafka 消息过期时间设置与清理机制全解析 在消息中间件的实际应用中,消息过期是一个绕不开的话题。无论是日志数据的定期清理、业务事件的临时存储,还是磁盘空间的合理管控,都需要一个完善的消息过期机制。Kafka 作为高吞吐的分布式消息系统,提供了... 国内服务器 1个月前170