RabbitMQ 消息顺序性保障:如何保证消息严格有序? 在很多业务场景下,消息必须严格按照发送顺序消费,比如:订单创建 → 支付 → 发货 → 完成;库存扣减 → 库存回补;日志按时间顺序入库等。但 RabbitMQ默认不保证全局顺序,如果不做特殊处理,就... 国内服务器 4周前130
Spark 课程核心知识点复习汇总 Spark核心概念包括弹性分布式数据集(RDD)、流处理(Spark Streaming)、PageRank算法和机器学习库(MLlib)。环境配置涵盖单机伪分布式集群搭建步骤,包括JDK安装、Spa... 国内服务器 4周前130
华为悦盒Q21/EC6109U免拆机刷机教程:海思MV200芯片一键刷入当贝桌面(附固件包) 本文提供华为悦盒Q21/EC6109U免拆机刷机详细教程,适用于海思MV200芯片设备一键刷入当贝桌面系统。教程包含准备工作、短接刷机步骤、首次设置及优化技巧,帮助用户轻松解锁设备潜能,获得更流畅的电... 国内服务器 4周前130
在大数据领域 Redis 与其他缓存工具的对比分析 在大数据时代,数据量呈现爆炸式增长,对数据的处理速度和效率有了更高的要求。缓存工具就像是数据的“小仓库”,可以把经常使用的数据存放在离我们更近的地方,这样获取数据的速度就会大大提高。本文的目的就是详细... 国内服务器 4周前130
Hive – 安装与使用 (1)hive 简介Hive:由 Facebook 开源用于解决海量结构化日志的数据统计工具。Hive 是基于 Hadoop 的一个数据仓库工具,可以将结构化的数据文件映射为一张表,并 提供类 SQL... 国内服务器 4周前130
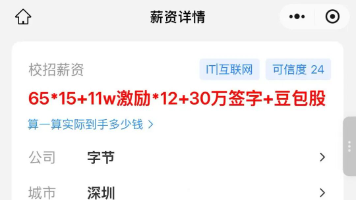
2026字节跳动大数据架构师面经:谓词下推与Flink状态深度解析 本文分享了字节跳动大数据架构师面试的核心知识点,包括SQL谓词下推技术和Flink状态管理机制。谓词下推通过提前过滤数据优化查询性能,文中通过SQL示例和原理图进行了详细说明。Flink状态管理部分重... 国内服务器# Langchain 4周前130
Flink 系列第 3 篇:核心概念精讲|分布式缓存 + 重启策略 + 并行度 底层原理 + 代码实战 + 生产规范 本文介绍了Flink三个核心功能:分布式缓存、故障恢复与重启策略、并行度配置。分布式缓存通过预加载小文件实现本地关联,优化大表Join性能;故障恢复支持局部重启降低影响,提供无重启、固定延迟和失败率三... 国内服务器 4周前130
大数据计算机毕设之基于python的深度学习音乐推荐系统基于Python+Django的深度学习个性化音乐推荐系统(完整前后端代码+说明文档+LW,调试定制等) 主要内容:免费开题报告、任务书、全bao定制+中期检查PPT、代码编写、🚢文编写和辅导、🚢文降重、长期答辩答疑辅导、一对一专业代码讲解辅导答辩、模拟答辩演练、和理解代码逻辑思路。 国内服务器 1个月前130
(赠源码)写真馆在线管理系统77939-( java、PHP、python、C#、小程序、机器学习、大数据、深度学习、爬虫,大屏可视化、文案全套、毕设定制/成品等) 本文设计并实现了一个基于SSM框架的写真馆在线管理系统,旨在解决传统写真馆面临的数字化转型需求。系统采用MySQL数据库,实现了用户注册登录、摄影项目浏览预约、留言反馈等前台功能,以及用户管理、摄影项... 国内服务器 1个月前130
Spark Shuffle优化:提升大数据处理性能的关键 本文旨在全面解析Spark Shuffle的工作原理和性能优化技术。我们将深入探讨Shuffle操作在Spark作业中的关键作用,分析其性能瓶颈,并提供一系列经过验证的优化策略。范围涵盖从基础概念到高... 国内服务器 1个月前130