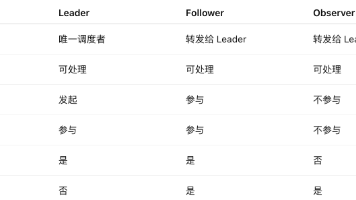
Leader、Follower、Observer 到底谁是老大?一篇讲透 Zookeeper 服务器角色 面试官突然一问:“说说 Zookeeper 服务器角色?”你脑袋一懵,只记得 Leader、Follower、Observer,却讲不清谁干啥。别慌,今天小米带你用一场“动物王国大会”的故事,把 Zo... 国内服务器 1个月前110
大数据领域数据中台的自动化测试方案 创建# 默认参数:任务所有者、开始时间、重试策略# 定义DAG:每日凌晨3点执行with DAG(catchup=False # 不执行历史任务) as dag:# 任务1:同步源数据到ODS层(假设... 国内服务器 2个月前110
Git archive导出纯净代码包 通过git archive生成纯净代码包,结合预配置的PyTorch-CUDA容器镜像,实现从开发到部署的环境一致性与代码可靠性。该方案有效避免依赖冲突、敏感信息泄露和GPU支持缺失等问题,确保AI模... 国内服务器 1个月前110
计算机毕业设计hadoop+spark+hive 高考志愿填报推荐推荐系统 高考数据分析可视化大屏 高考爬虫 高考分数线预测 数据仓库 大数据毕业设计 摘要:本项目基于Hadoop+Spark+Hive技术栈开发高考志愿填报推荐系统,整合历年录取数据、院校信息等多源数据,利用Spark进行实时数据处理和机器学习算法实现个性化推荐。系统包含数据存储(H... 国内服务器 2个月前110
大数据里Zookeeper:数据同步的实现原理 Zookeeper的数据同步,本质上是分布式系统中“一致性”的具象化——通过一套严格的规则,让多个节点的状态保持一致。它的价值,不是“存储数据”,而是“让分布式系统的各个部分,像一个整体一样工作”。如... 国内服务器 1周前100
大数据领域Kafka的消息堆积问题解决 在大数据时代,Kafka作为一款高性能、分布式的消息队列系统,被广泛应用于日志收集、实时数据处理、流式计算等众多场景。然而,消息堆积问题时常困扰着开发者和运维人员。本文章的目的在于深入探讨Kafka消... 国内服务器 2周前100
大数据领域Doris与Spark的协同工作模式 能力维度DorisSpark实时查询速度毫秒级(强)秒级(弱)离线ETL复杂度简单处理(弱)复杂处理(强)高并发支持支持(强)不支持(弱)生态对接能力有限(主要对接存储)丰富(对接所有大数据组件)结论... 国内服务器 2周前100
借助 Kafka 提升大数据平台的实时响应能力 Kafka是一个分布式流处理平台发布/订阅:像消息队列一样,生产者发消息,消费者收消息;持久化存储:消息会被持久化到磁盘,不会丢(除非手动删除);流处理:支持实时处理消息(比如用Kafka Strea... 国内服务器 2周前100
RabbitMQ 延迟消息实现:两种方案全解析(TTL+死信 / 延迟插件)实战教程 在实际业务开发中,延迟消息是非常高频的需求:订单超时未支付自动取消、用户注册30分钟未完善资料提醒、外卖超时自动退款、预约任务定时执行等。RabbitMQ本身不直接提供延迟队列,但可以通过两种成熟方案... 国内服务器 2周前100