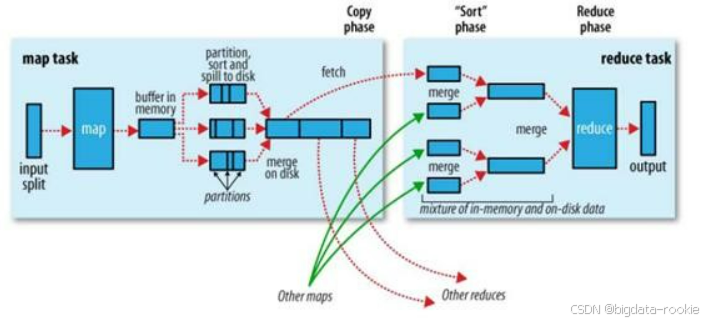
Spark shuffle 和 MapReduce shuffle 的区别 shuffle 的字面意思是洗牌、混洗的意思,就是把一组有规律的数据尽量打乱成无规律的数据。但在 MapReduce 中 Shuffle 更像是洗牌的逆过程,其将 Map 端输出的混乱数据按指定规则划... 国内服务器 2周前60
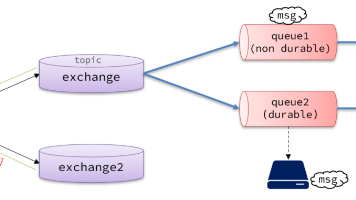
【微服务 Day6】SpringCloud实战开发(RabbitMQ高级篇 + 死信交换机、延迟消息) 本文探讨了如何确保RabbitMQ消息的可靠性,解决支付服务与交易服务数据不一致问题。主要内容包括:1)生产者可靠性:通过重试机制和确认机制确保消息成功发送;2)MQ可靠性:采用持久化和LazyQue... 国内服务器 4天前50
Kafka Streams性能调优实战(延迟降低90%的秘密武器) 掌握Kafka Streams实时处理延迟优化秘诀,实战经验助你延迟降低90%。涵盖流式计算常见瓶颈、状态存储调优与并行度提升策略,适用于高并发场景。方法可复用,效果显著,值得收藏。 国内服务器 4天前50
HBase 2.4.18 分布式集群搭建教程(适配 Hadoop 3.3.4 + ZooKeeper 3.5.6) 摘要:本文详细介绍了HBase 2.4.18在Hadoop 3.3.4集群上的分布式安装配置过程。主要内容包括:环境准备(Hadoop、ZooKeeper集群搭建)、HBase核心配置文件修改(hba... 国内服务器 1周前50
(附源码)spark音乐推荐系统-计算机毕设 42921 普通用户功能分析登录注册:普通用户可以通过登录或注册账户来使用系统的各项服务。登录后的用户可以访问个性化的音乐推荐、参与论坛讨论、管理自己的账户等功能。系统可能采用用户邮箱或手机号作为注册的基础,确保... 国内服务器 1周前50
计算机毕业设计hadoop+spark+hive地震预测系统 地震数据可视化分析 大数据毕业设计(源码+LW文档+PPT+讲解) 本文提出基于Hadoop+Spark+Hive的地震预测系统,旨在解决传统方法在数据规模增长下的扩展性差、预测延迟高问题。系统通过多源异构数据融合(地质、气象、动物行为等),采用混合预测模型(物理模型... 国内服务器 1周前50
探索大数据领域存算分离的技术趋势 本文旨在全面分析大数据领域中存算分离架构的技术原理、实现方式和发展趋势。我们将探讨这一技术如何解决传统大数据架构中的资源利用率低下、扩展性受限等问题,并详细阐述其在云计算环境下的最佳实践。文章首先介绍... 国内服务器 4天前40
Kafka Streams聚合操作进阶之路(掌握State Store与Windowing精髓) 掌握Kafka Streams聚合操作的核心技巧,解决实时数据统计难题。深入解析State Store状态管理与Windowing窗口机制,涵盖滚动窗口、会话窗口等应用场景,提升流处理效率。理解持久化... 国内服务器 4天前40
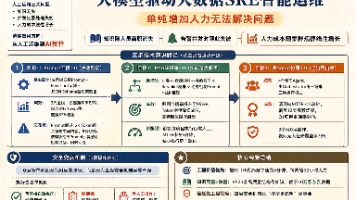
大模型驱动大数据SRE智能运维 【摘要】网易云音乐SRE团队通过AI技术实现运维自动化三级跳:从初期Prompt工程实现85%归因准确率,到RAG知识库将准确率提升至95%,最终构建多Agent协同系统实现全链路自愈。该系统将故障处... 国内服务器 4天前40
【MQ】你知道RocketMQ与Kafka的核心差异有哪些吗?提供面试速记版 本文对比了RocketMQ与Kafka的核心特性,并针对消息中间件的常见异常提供了解决方案。RocketMQ侧重金融级可靠性和低延迟,支持事务消息;Kafka则更适合大数据场景的高吞吐需求。文章详细分... 国内服务器 4天前40