Kafka Python 客户端实战:消费位移管理的可靠性陷阱与 Exactly-Once 语义实现 Kafka Python 客户端的可靠消费不是配置问题,而是架构问题。位移提交的时机、幂等性的实现、重平衡的处理,每一个环节都需要在吞吐量与一致性之间做出明确的权衡。位移提交策略得跟业务需求匹配。先处... 国内服务器 3周前150
从日志到 HBase:用 Flume、Kafka、Flink 串起一条实时数据链路 从日志到 HBase 的这条实时链路,是大数据入门的一个经典实验。把 Flume、Kafka、Flink 串起来跑通之后,再去看生产架构会清晰很多。如果你在搭建过程中遇到问题,或者有自己想尝试的链路组... 国内服务器 4周前170
ArchivePasswordTestTool:智能压缩包密码找回工具终极指南 你是否曾经因为忘记压缩包密码而无法访问重要文件?ArchivePasswordTestTool正是为你解决这一困扰的专业工具。这款基于7zip引擎的开源软件能够自动化测试密码字典,帮你快速找回丢失的压... 国内服务器 3周前180
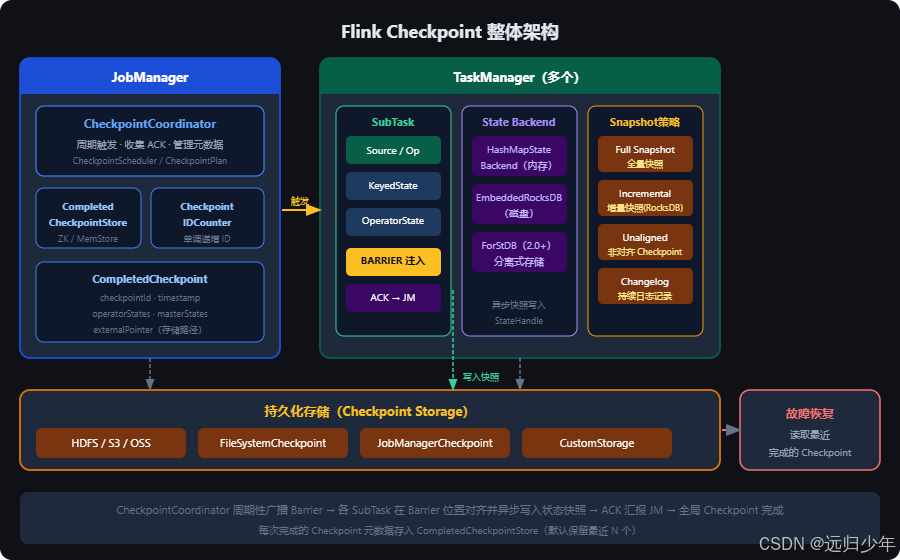
Apache Flink Checkpoint 与 Chandy-Lamport 算法深度解析 本文系统梳理了Flink Checkpoint机制的核心原理与实现。Checkpoint作为Flink容错的核心组件,通过周期性全局快照实现Exactly-Once语义。文章详细解析了Checkpoi... 国内服务器 4周前190
flink接入spring体系 注意的是SpringApplicationContext要保证进程单例, 不要在算子的open()方法中创建SpringApplicationContext, 否则在并行执行算子时会导致重复创建Spr... 国内服务器 3周前180
【黑产大数据】2025年全球电商业务欺诈风险研究报告 2025年,威胁猎人监测全球电商风险线索达1500万条、黑灰产相关帐号160万个,风险高度集中于欧洲、中国与美国,黑灰产针对全球电商平台的攻击方式,均深度贴合平台业务流程,形成覆盖账号、货源、履约与售... 国内服务器 4周前190
扒一扒 Kafka 的“四大天王“:Broker、Topic、Partition、Replica 到底啥关系? 来来来,咱把四者关系串起来:Kafka 概念生活类比Broker货架(服务器),实际存包裹的Topic货品分类标签(生鲜区、电器区)Partition一个分类下的多个货架层(每层独立放货、独立取货)R... 国内服务器 3周前200
Spark Datafusion Comet 向量化Rust Native–执行Datafusion计划 摘要 Apache Datafusion Comet是苹果开源的Spark向量化加速项目,采用Spark插件化+Protobuf+Arrow+DataFusion架构。项目通过SparkPlugin实... 国内服务器 4周前190