Spark Shuffle优化:提升大数据处理性能的关键 本文旨在全面解析Spark Shuffle的工作原理和性能优化技术。我们将深入探讨Shuffle操作在Spark作业中的关键作用,分析其性能瓶颈,并提供一系列经过验证的优化策略。范围涵盖从基础概念到高... 国内服务器 4周前110
【西瓜带你学Kafka | 第五期】Kafka 副本同步机制与集群健康管理:ISR、故障选举与关键配置(文含图解) 本文围绕 Kafka 副本同步与集群管理展开,详解 AR、ISR、OSR 三组副本的概念与动态流转机制,分析副本被踢出 ISR 的条件与 Leader 宕机时的选举策略,讲解 Broker 有效性的判... 国内服务器 4周前150
【Kafka 进阶之路】详解 Kafka 副本机制 LEO (Log End Offset):副本本地日志最后一条消息的偏移量 + 1(下一条待写入位置)HW (High Watermark):所有 ISR 副本已同步完成的消息最大偏移量,消费者只能读... 国内服务器 3周前170
揭秘大数据领域数据预处理的奥秘 数据预处理是大数据分析流程中至关重要的一环,通常占据了整个数据分析项目70%以上的时间和精力。本文旨在全面剖析数据预处理的各个环节,帮助读者掌握构建高效数据预处理流水线的核心技能。本文将按照数据预处理... 国内服务器 4周前100
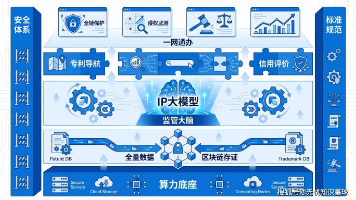
某市“十五五“知识产权大数据监管平台与全链条保护系统建设方案深度解读(WORD) 本方案是一份针对政务数字化转型的“智慧知识产权大数据平台”超大型建设方案,适用于省市级知识产权局、市场监管部门及高新园区的重大信息化项目立项与顶层设计。适用于政府信息化主管、智慧政务架构师及项目申报团... 国内服务器 4周前110
Docker部署Hadoop-03-Docker部署Hadoop 本文完成基于docker的hadoop3.3.0安装 目前数据存放在docker的内部文件系统中,还没有进行挂载卷 国内服务器 4周前130
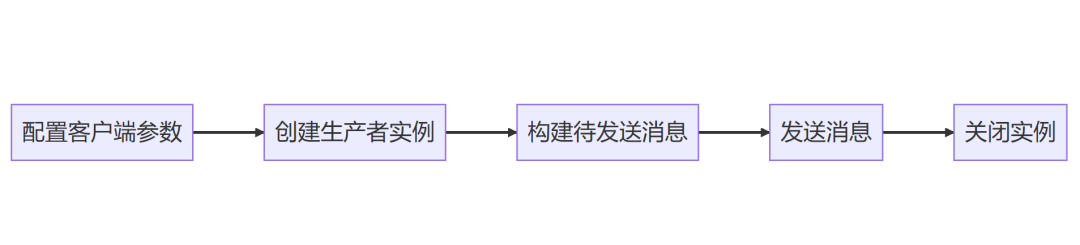
C++如何实现Kafka生产者客户端?10 分钟构建第一个应用 Kafka 集群的连接地址,生产者通过这些地址发现 Kafka 集群。可以配置多个地址,以提高可用性。: 将消息的 Key 序列化成字节数组的类。: 将消息的 Value 序列化成字节数组的类。ack... 国内服务器 4周前170
大数据处理中 Kafka 的安全配置与防护 客户端连接broker时,会先验证broker的身份(通过证书);双方协商生成一个“会话密钥”,后续所有数据都用这个密钥加密传输。SASL是Kafka的认证框架PLAIN:简单用户名密码(明文传输,仅... 国内服务器 4周前120
【信息科学与工程学】【通信工程】第七十二篇 RoCE网络交换机模型12 涵盖网络优化、安全、可视化、可编程网络、网络测量、网络切片、网络安全、网络自动化、网络仿真、网络AI运维等领域,并与RDMA、SDN、数据中心网络紧密结合。编号领域核心理论模型/协议/算法名称... 国内服务器 4周前130
大数据-278 Spark MLib-GBDT梯度提升决策树详解:从原理到实战案例 GBDT是Boosting家族的核心算法,通过多棵决策树逐步拟合残差来减少预测误差。2024年主流版本如XGBoost、LightGBM均基于此思想扩展。本文以身高预测为案例,详解初始化学习器(均值... 国内服务器 4周前140