【微服务学习笔记】Windows 安装 RabbitMQ(含 Erlang 环境配置) 本文介绍了RabbitMQ的安装配置流程:首先需安装Erlang并配置环境变量;其次下载安装RabbitMQ,注意安装路径需为具体子目录;然后配置环境变量并验证服务运行;接着启用管理插件,通过1567... 国内服务器 1个月前150
【后端开发】RabbitMQ、RocketMQ、Kafka 怎么选?我从业务场景重新梳理了一遍 关于三种消息队列 RabbitMQ、RocketMQ和Kafka 如何选择,刚开始学消息队列的时候,我其实也很容易陷入一种误区:把 RabbitMQ、RocketMQ、Kafka 放在一张表里硬背。比... 国内服务器 1个月前150
大数据领域数据清洗的实践经验总结 数据清洗是大数据处理流程中至关重要的一环,它直接影响后续数据分析的准确性和可靠性。本文旨在系统性地总结大数据领域中数据清洗的核心技术、常见问题和实践经验,为数据从业者提供全面的参考指南。数据清洗的基本... 国内服务器 1个月前90
数据科学在大数据领域的能源数据管理 随着全球能源需求的持续增长和可再生能源的快速发展,能源数据管理已成为一个关键的研究领域。本文旨在探讨如何利用数据科学技术处理和分析海量能源数据,实现更高效的能源管理、预测和优化。能源数据的特点和挑战大... 国内服务器 1个月前80
Flink CLI 从提交作业到 Savepoint/Checkpoint、再到 YARN/K8S 与 PyFlink 本文介绍了Apache Flink CLI工具的核心使用场景和实用技巧,主要包括:1) 提交作业的run命令及其参数配置;2) 作业监控list命令;3) Savepoint操作与管理;4) Chec... 国内服务器 1个月前130
Docker快速部署HBase:从零搭建到Java应用集成 本文详细介绍了如何使用Docker快速部署HBase并集成Java应用。通过Docker容器化技术,开发者可以轻松搭建HBase单机环境,避免复杂的依赖配置,并实现高效的Java应用集成。文章还提供了... 国内服务器 1个月前150
大数据领域数据架构的数据治理体系 在当今数字化时代,大数据已经成为企业和组织的重要资产。随着数据量的爆炸式增长,数据的复杂性和多样性也日益增加。数据治理体系的目的在于确保数据的质量、安全性、合规性和可用性,提高数据的价值和利用率。本文... 国内服务器 1个月前150
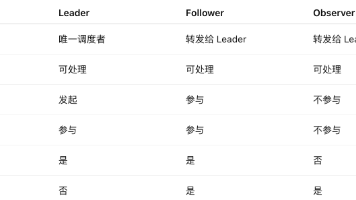
Leader、Follower、Observer 到底谁是老大?一篇讲透 Zookeeper 服务器角色 面试官突然一问:“说说 Zookeeper 服务器角色?”你脑袋一懵,只记得 Leader、Follower、Observer,却讲不清谁干啥。别慌,今天小米带你用一场“动物王国大会”的故事,把 Zo... 国内服务器 1个月前110
重生之我创作出了小红书:如何解决万级流量带来的问题?Canal+kafka+MySQL(OutBox) 传统方式(直接调用)你告诉服务员要什么菜服务员立刻跑到厨房告诉厨师厨师开始做菜服务员站在厨房等菜做好服务员再把菜端给你问题:如果厨师很忙,服务员要一直等,其他客人就没人服务了。Outbox 方式(事件... 国内服务器 1个月前100
基于Spark的协同过滤推荐系统操作指南 利用Spark构建推荐系统,重点讲解协同过滤算法的操作步骤与实战技巧,帮助快速掌握大规模数据下的推荐模型训练与预测过程。涵盖数据预处理、模型训练与评估等关键环节,适用于推荐系统开发与优化。 国内服务器 1个月前120