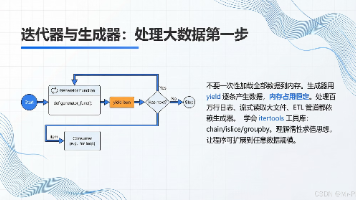
第十六章 迭代器与生成器:处理大数据的第一步 本章介绍了迭代器与生成器在处理大数据时的关键作用。核心思想是将"批量一次性处理"转变为"流式逐条处理",通过惰性计算显著降低内存... 国内服务器 4个月前490
【大数据技术基础 | 实验七】HBase实验:部署HBase 本实验介绍HBase体系架构和部署HBase的相关实验步骤。理解HBase基础简介及体系架构,掌握HBase集群安装部署及HBase Shell的常用命令,了解HBase和HDFS及Zookeeper... 国内服务器 5个月前490
Flink State Processor API 读写/修复 Savepoint,把“状态”当成可查询的数据 在 Flink 里,算子逻辑可以重写,但“状态”(State)一旦跑起来就像长在系统里:想改数据结构、改并行度、修脏数据、给新算子补历史状态……传统做法往往意味着“丢状态重跑”。State Proce... 国内服务器 5个月前490
大数据新视界 — 大数据大厂之 Hive 函数库:丰富函数助力数据处理(上)(11/ 30) 本文承前启后,深度剖析 Hive 函数库,涵盖分类体系、常用函数、优化技巧,佐以经典案例、详实代码与测试数据,具实操与参考价值,设互动并预告下篇。 国内服务器 5个月前490
大数据Apache Doris从入门到入土(一) Apache Doris是一款基于MPP架构的高性能、实时分析型数据库。它以高效、简单和统一的特性著称,能够在亚秒级的时间内返回海量数据的查询结果。Doris既能支持高并发的点查询场景,也能支持高吞吐... 国内服务器 4个月前490
HBase完全分布式部署详细教程(含HA高可用版+普通非HA版) HBase完全分布式的两种部署方案:HA高可用版(含备用HMaster,适配Hadoop HA集群)和普通非HA版(配置简洁,适配普通Hadoop完全分布式集群) 国内服务器 5个月前490
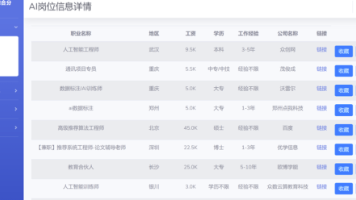
基于hadoop的招聘网站数据分析与可视化系统【开源代码】 本文设计并实现了一个基于Hadoop生态的招聘数据分析与可视化系统。系统通过爬虫获取多源招聘数据,利用HDFS存储,Hive构建数据仓库,Spark进行分布式处理分析,最终通过SpringBoot+V... 国内服务器 5个月前490
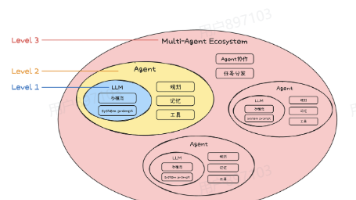
从零开始搞定 AI Agent 搭建全流程 本文系统介绍了AI Agent的生态体系,包括协议标准、思考框架和开发框架三大核心内容。在协议层面,重点分析了面向上下文的MCP协议和面向Agent间协作的A2A协议,阐述了标准化协议在互操作性、可扩... 国内服务器 5个月前490
【Isaacim和Isaaclab安装】NVIDIA DGX Spark(Ubuntu24.04)安装isaacim5.1.0+isaaclab 本文详细介绍了在NVIDIA DGX Spark(Ubuntu 24.04 LTS 架构)上安装Isaac Sim和Isaac Lab的完整流程。主要内容包括:1)下载安装ARM64版Minicond... 国内服务器 5个月前490
OPPO手机技巧:如何恢复OPPO手机数据 OPPO 手机以其出色的视觉效果、出色的摄像头、超大的内部存储空间以及广阔的外部存储空间而闻名。虽然这些功能激励用户存储个人、教育和专业数据,但它们也可能成为其败笔。用户有时会被锁定或将 OPPO 手... 国内服务器 5个月前490