如何把豆包的回答导出文件 摘要: AI助手豆包的高效响应常面临内容导出难题——截图不可检索,复制粘贴易丢失格式,手动整理耗时。针对这一痛点,DS随心转插件提供了轻量解决方案:支持一键导出豆包回答为PDF、Word等格式,保留代... 国内服务器 6个月前1230
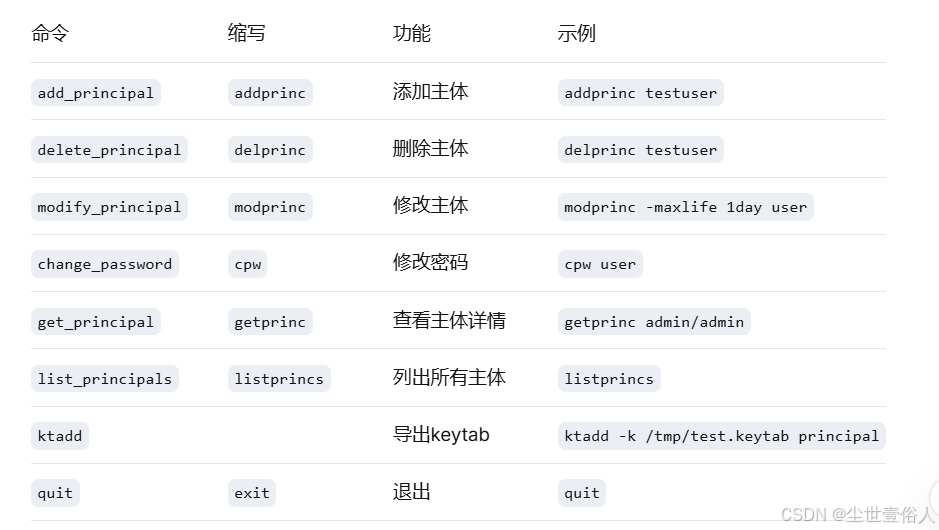
Zookeeper、Hadoop、Hive、Spark、Presto配置Kerberos 本文介绍了Kerberos认证系统在Hadoop集群中的部署与应用。Kerberos通过KDC(票据发放中心)解决企业级安全两大问题:细粒度服务访问控制和凭证有效性验证。部署过程包括:1)准备4台服务... 国内服务器 5个月前1200
Java 大视界 — Java 大数据在智能医疗临床路径优化与医疗资源合理利用中的应用(424) 本文探讨了Java大数据技术在智能医疗临床路径优化与医疗资源合理利用中的应用。文章首先分析了当前医疗行业面临的三大核心痛点:临床路径的固化滞后问题导致诊疗方案缺乏个性化;医疗资源调度失衡造成设备闲置与... 国内服务器 5个月前1170
2026开年炸雷!Apache Kafka三重高危漏洞肆虐:RCE+DoS+SSRF齐发,波及2.0.0-3.9.0全版本,企业升级刻不容缓 漏洞编号漏洞类型危害等级影响范围CVSS评分核心危害关联性任意文件读取+SSRF高危9.1可作为前置攻击跳板,窃取密钥、内网拓扑等敏感信息,为后续RCE攻击铺路严重9.8直接接管数据同步组件,篡改业务... 国内服务器 6个月前1170
【大数据】open_metadata 开源元数据管理平台建设与数据血缘实践 随着业务数据持续涌入大数据平台,数据上下游依赖关系日益复杂,业务对报表数据溯源困难,传统的管理方式已难以满足追溯与治理需求。需要引入元数据血缘,实现对数据从源头到消费端的全链路追踪,精准刻画数据的生成... 国内服务器 6个月前1170
Java 大视界 — Java+Spark 构建离线数据仓库:分层设计与 ETL 开发实战(445) 本文摘要(148字): 本文分享了Java+Spark构建离线数据仓库的实战经验。首先解析了分层设计的核心价值,通过ODS→DWD→DWS→ADS四层架构实现数据解耦与高效查询,结合真实案例展示分层后... 国内服务器 6个月前1150
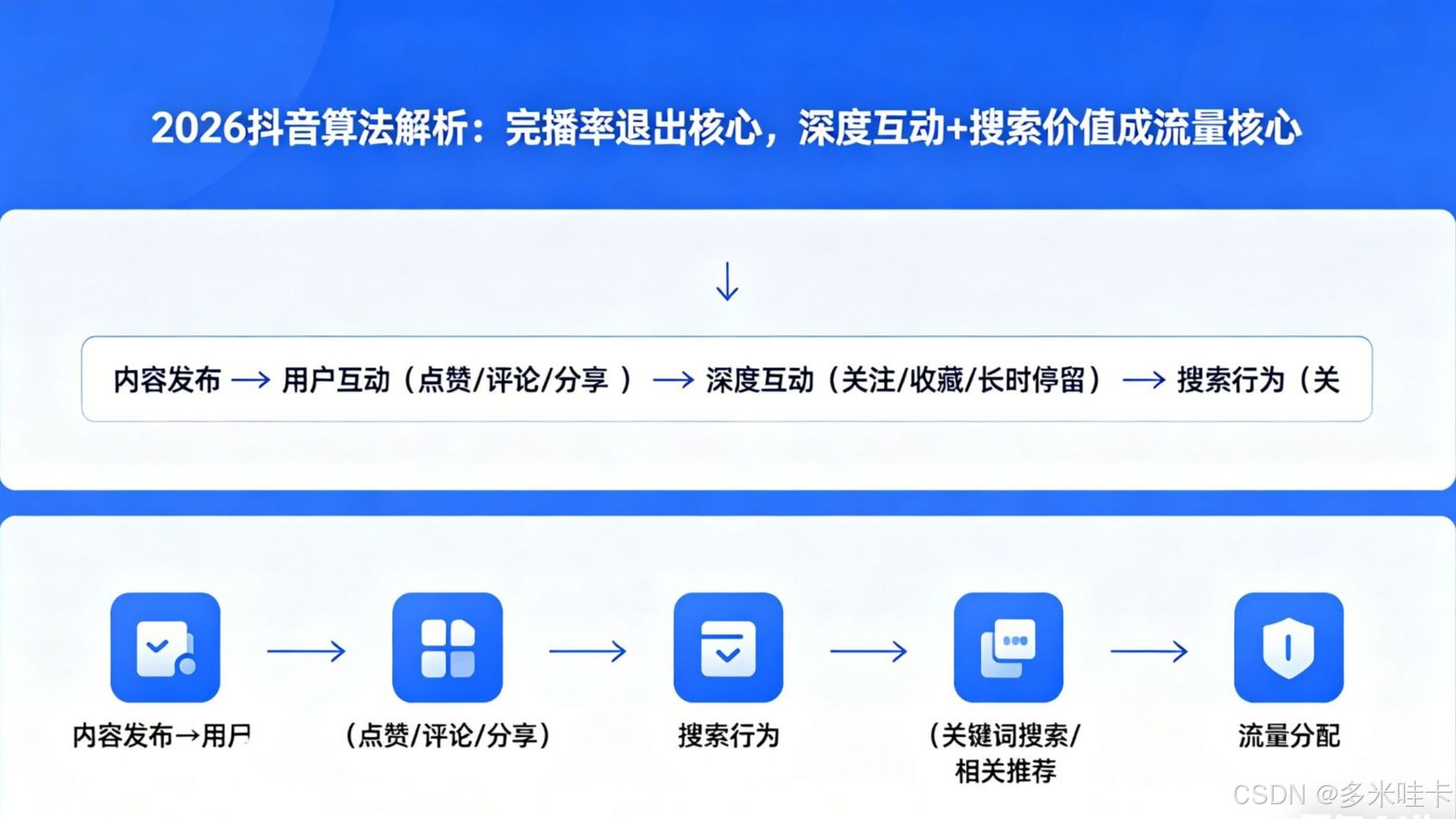
2026抖音算法解析:完播率退出核心,深度互动+搜索价值成流量核心 还在执着于完播率?2026年抖音算法已转向“深度互动+搜索价值”,多数运营尚未吃透新规要点。这篇实操干货,详细拆解适配新逻辑的方法,助力运营者合理获取流量。 国内服务器 2个月前1140
【AI+手工/自动化测试】— 测试全流程解析+自动化测试(从需求分析到测试报告的完整学习记录,解锁AI工具如何赋能测试) 该内容主要围绕手工AI自动化测试的速成教程展开。\详细讲解了AI工具DeepSeek的三种模式及其在测试中的应用,如编写测试计划、设计测试用例、描述缺陷和编写测试报告等。还展示了如何利用AI工具进行自... 国内服务器 6个月前1140
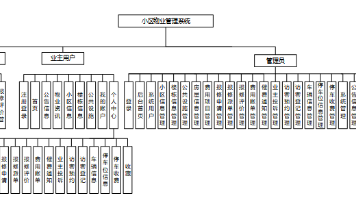
【Java小区物业管理系统】(免费领源码+演示录像)|可做计算机毕设Java、Python、PHP、小程序APP、C#、爬虫大数据、单片机、文案 该系统采用了Spring Boot作为核心框架,结合了MySQL数据库用于数据存储,以及Thymeleaf模板引擎实现动态网页展示。设计上,系统集成了用户注册登录、公告信息发布、物业费用管理、报修申请... 国内服务器 5个月前1120
Windows安装Apache Kafka保姆级教程(图文详解+可视化管理工具) 通过本教程,我们成功在Windows系统上完成了Apache Kafka的完整安装和配置,包括Java环境准备、Kafka下载解压、配置文件修改、服务启动、功能测试以及可选的Windows服务配置。现... 国内服务器 6个月前1120