OpenClaw(养龙虾) +关于Hadoop hive的Skills(CLoudera CDH、CDP) 摘要:OpenClaw生态未内置Hadoop/Hive专用技能,因其企业级特性难以通用化。建议通过组合基础技能实现操作:1)使用tmux/session-logs管理长时任务;2)通过shell/ex... 国内服务器 2个月前210
Spark-Submit参数介绍及任务资源使用测试 yarn-client模式中,通过指定“--num-executors”参数则默认为Spark任务启动2个Executor;提交任务后,可以通过WebUI查看当前Application使用资源情况:A... 国内服务器 2个月前180
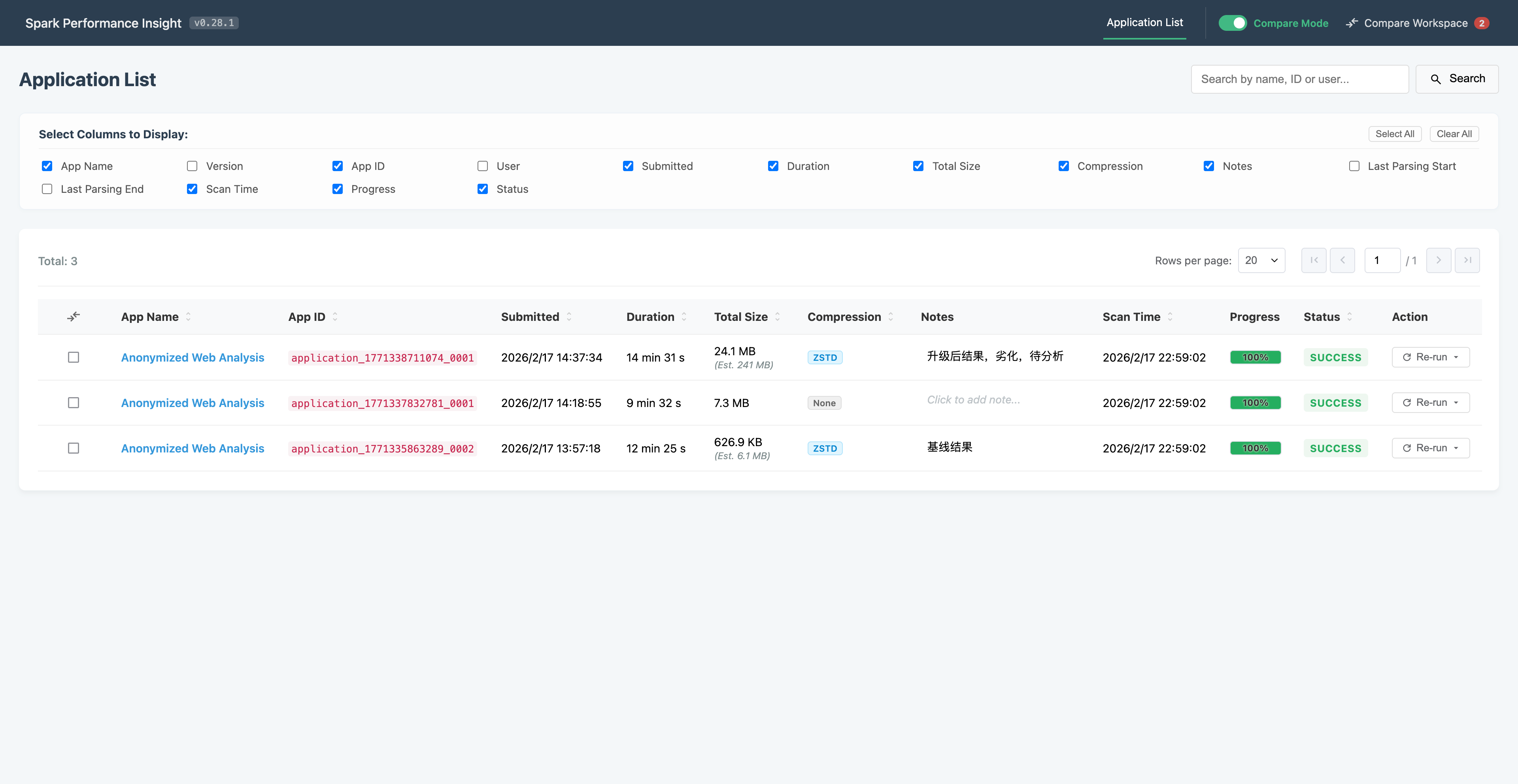
从“吐槽”到“交付”——我是如何协同 AI 撸出一个 Spark 性能分析工具的(上) 本文记录了一位后端开发者利用AI协作在3周内完成Spark性能分析工具开发的真实经历。通过"吐槽驱动开发"模式,作者实现了三大突破:跨越10年前端技术断层、24倍性... 国内服务器 1个月前210
【Filebeat+Kafka+ELK企业级日志系统实战部署:详解Kafka、Filebeat核心知识与ELK集成场景,Kafka集群部署、组件配置与验证,Filebeat部署及Kibana可视化】 本文介绍在ELK系统中加入Kafka和Filebeat的部署方案。Kafka作为高吞吐量消息队列,实现日志缓冲和削峰填谷;Filebeat作为轻量级日志采集工具,负责实时采集并转发日志至Kafka。文... 国内服务器 2个月前190
大数据领域的分布式文件系统 在大数据时代,数据量呈现爆炸式增长,传统的文件系统难以满足大规模数据存储和高效访问的需求。分布式文件系统应运而生,它将数据分散存储在多个节点上,通过网络进行统一管理和访问,提高了数据的可靠性、可扩展性... 国内服务器 2个月前190
Python大数据可视化:基于大数据技术的共享单车数据分析与辅助管理系统_flask+hadoop+spider 在搭建过程中,最开始的工作是从查阅相关资料开始的,通过在互联网的共享单车数据分析与辅助管理系统资料查询和阅读,对整个共享单车数据分析与辅助管理系统有了整体的概念了解,然后对本共享单车数据分析与辅助管理... 国内服务器 2个月前160
基于Python大数据旅游数据分析与推荐系统的爬虫 数据分析可视化系统 该系统基于Python技术栈构建,整合了网络爬虫、大数据分析、机器学习推荐算法及可视化技术,旨在为旅游行业提供数据驱动的决策支持与个性化服务。数据采集层采用Scrapy框架爬取主流旅游平台(如携程、T... 国内服务器 2个月前180
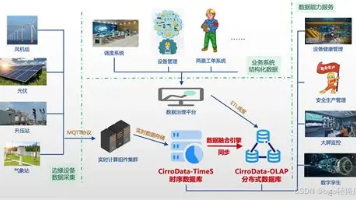
2026时序数据库选型全指南:大数据场景下的国产最优解,IoTDB实力领跑 随着工业物联网、智慧城市等领域时序数据爆发式增长,时序数据库成为大数据架构核心组件。本文提出时序数据库选型六大维度:高吞吐写入、高效存储压缩、快速查询、轻量化扩展、生态兼容及本土化服务。重点推荐国产开... 国内服务器 2个月前180
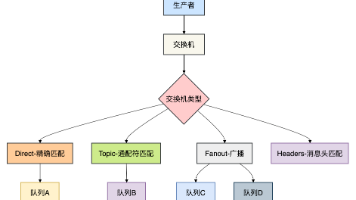
RabbitMQ和RocketMQ,哪个更好? 最近有球友问我:苏三哥,现在一般的项目中的消息中间件,是用RabbitMQ,还是RocketMQ,更好?这是一个非常常见的问题。今天这篇文章就专门跟大家一起聊聊这个话题,希望对你会有所帮助。Rabbi... 国内服务器 2个月前180