Flink External Resource Framework让作业“原生”申请 GPU/FPGA 等外部资源 Flink外部资源框架主要用于资源请求改写和资源信息提供,支持GPU、FPGA等专用硬件加速。框架通过插件机制加载资源驱动,在Kubernetes/YARN/Standalone环境下实现资源申请和分... 国内服务器 2个月前140
用Druid做实时大数据描述性分析 想象一下,你身处一家大型电商公司,每天有成千上万的用户在平台上浏览商品、下单购买。公司的管理层急需了解用户的行为模式,比如平均购买金额是多少,哪些商品最受欢迎,不同时间段的用户活跃度如何等。这些信息对... 国内服务器 2个月前190
大数据简介 摘要:本文介绍了大数据的基本概念、特点和应用场景。大数据指有价值的海量数据,通常以GB/TB为单位,解决传统工具无法处理的数据存储和计算问题。其特点包括数据类型多样(结构化、非结构化、半结构化)、来源... 国内服务器 2个月前170
通信协议仿真:5G NR协议仿真_(25).5G NR仿真中的云计算与大数据 在5G NR仿真中,云计算和大数据技术的结合为研究人员和工程师提供了强大的工具,使得复杂的仿真任务可以高效、可靠地完成。通过云计算的资源弹性、成本效益、可扩展性和高可用性,可以轻松管理大规模的仿真任务... 国内服务器 2个月前170
Spring Boot 与 Kafka:消息可靠性传输与幂等性设计的终极实战 本文深入探讨了在Spring Boot与Kafka集成中实现消息可靠性传输与幂等性设计的核心策略。首先分析了生产者端的ACK机制三重境界(0/1/all)及其可靠性权衡,并详解了幂等性生产者通过PID... 国内服务器 2个月前160
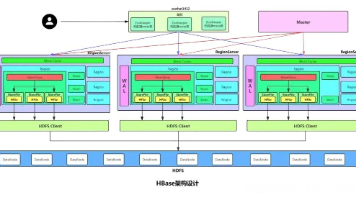
HBase 原理深度剖析:从数据模型到存储机制 本文深入剖析了HBase分布式数据库的核心原理,主要包含以下内容:1) HBase是基于HDFS的列式存储NoSQL数据库,适用于海量数据随机读写场景;2) 详细解析HBase表结构设计,包括RowK... 国内服务器 2个月前110
Hadoop数据去重:处理重复记录的技巧 在当今数字化时代,数据量呈现爆炸式增长,企业和组织每天都会产生大量的数据。这些数据中不可避免地会存在重复记录,重复数据不仅会占用大量的存储空间,还会影响数据处理的效率和准确性,增加数据处理的成本。因此... 国内服务器 2个月前160
Hadoop核心技术学习心得 以MapReduce为例,其Map阶段负责数据分片与局部处理,Reduce阶段负责全局聚合,这种“分而治之”的思路要求我们在编程时必须打破单机局限,重点思考数据如何拆分、Map任务与Reduce任务的... 国内服务器 2个月前180
数仓分层架构视角下的 Flink 多流关联剖析 以实时数仓 DWD、DWS 分层架构为核心,剖析 Flink 多流关联方案,结合业务场景、代码与生产避坑要点,帮你理清选型逻辑,搞定实时宽表与多源数据融合开发。 国内服务器 2个月前190
大数据领域分布式存储的语言数据存储与处理 随着全球数字化进程加速,语言数据(包括文本、语音、翻译数据等)的规模呈指数级增长。传统的数据存储和处理方法已无法满足需求,分布式存储和处理技术成为解决这一挑战的关键。本文旨在全面介绍大数据领域中语言数... 国内服务器 2个月前200