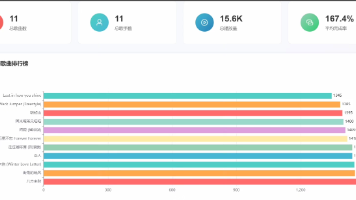
基于hive大数据技术的热门音乐数据分析平台完整实现、hive离线数仓、mysql数据存储、vue页面可视化 本项目实现了一个基于大数据技术的音乐数据分析平台,采用完整的大数据技术栈从数据清洗到可视化展示。系统架构包含数据存储层(HDFS)、计算层(MapReduce)、数据仓库(Hive)、数据导出(Sqo... 国内服务器 4个月前450
在 PySpark 中生成合成描述性数据 原文:towardsdatascience.com/methods-for-generating-synthetic-descriptive-data-c6678cc10aff? 国内服务器 4个月前450
Kafka Streams过滤模式深度解析(99%开发者忽略的关键细节) 掌握Kafka Streams数据过滤的高效实现方法,深入解析流处理中的精准过滤模式与性能优化策略。涵盖时间窗口、状态存储与条件筛选等关键应用场景,揭示99%开发者忽略的细节陷阱。提升实时处理准确性与... 国内服务器 4个月前450
探索大数据领域数据预处理的前沿技术 数据预处理是大数据分析流程中至关重要的一环,通常占据整个数据分析项目60%-80%的时间和精力。随着大数据技术的快速发展,数据预处理技术也在不断演进。本文旨在系统地介绍大数据预处理领域的前沿技术,包括... 国内服务器 4个月前450
【开题答辩全过程】以 基于hadoop的新能源汽车数据可视化分析系统为例,包含答辩的问题和答案 本文介绍了一位拥有14年经验的毕设指导专家,擅长Java、Python等多种开发语言,提供项目定制、代码讲解、答辩指导等服务。重点展示了一个新能源汽车数据可视化分析系统的毕业设计案例,该系统基于Had... 国内服务器 5个月前450
天外客AI翻译机ZooKeeper协调服务使用 本文深入探讨Apache ZooKeeper在“天外客AI翻译机”中的核心作用,解析其如何通过服务注册、配置热更新、主控选举和分布式锁等机制,保障分布式设备的稳定性与协同效率,并结合实战代码与避坑指南... 国内服务器 5个月前450
Flink源码阅读:Kafka Connector 本文分析了Flink Kafka Connector的实现原理。首先介绍了Flink自定义Source/Sink的三层架构:Metadata层处理表元数据,Planning层通过工厂类创建Dynami... 国内服务器 5个月前450
主流消息队列对比:Kafka vs RabbitMQ vs RocketMQ 本文对Kafka、RabbitMQ和RocketMQ三大主流消息队列进行了深度对比。Kafka采用分区模型和顺序I/O,适合高吞吐场景如日志收集和大数据分析;RabbitMQ基于AMQP协议和交换器模... 国内服务器 5个月前450
大数据领域 OLAP 在电信用户流失分析中的应用 本文旨在为电信行业数据分析师、大数据工程师和业务决策者提供一套完整的OLAP技术应用于用户流失分析的解决方案。我们将覆盖从数据准备、模型构建到分析应用的全流程。本文首先介绍OLAP和用户流失分析的基本... 国内服务器 5个月前450