数据服务如何赋能企业数字化转型?大数据视角 在“一切业务数据化,一切数据业务化”的今天,企业数字化转型已从“选择题”变为“必答题”。但许多企业面临这样的困境:数据像散落在各个角落的“珍珠”,却无法串成“项链”——采购、销售、生产、用户行为等数据... 国内服务器 5个月前450
4、Spark 函数_m/n/o/p/q/r Spark SQL提供了多个日期时间创建函数: make_date():根据年月日创建日期,支持1-9999年范围 make_dt_interval():通过天/时/分/秒创建时间间隔 make_in... 国内服务器 5个月前450
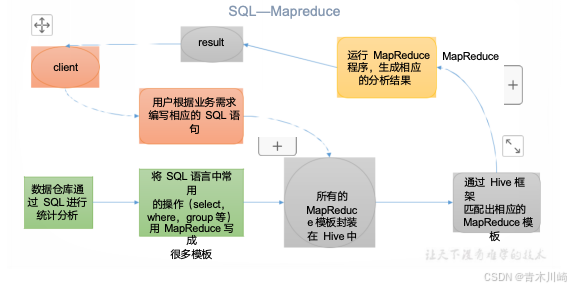
大数据技术之hive Hive:由 Facebook 开源用于解决海量结构化日志的数据统计工具。Hive 是基于 Hadoop 的一个数据仓库工具,可以将结构化的数据文件映射为一张表,并提供类SQL查询功能。创建一个数据库... 国内服务器 1个月前440
如何构建面向行业的大数据解决方案? 在“数据是新石油”的数字化时代,企业的核心竞争力正从“资源占有”转向“数据价值挖掘”。但许多企业面临“有数据无价值”的困境:传感器收集了海量设备数据却无法预测故障,用户行为日志堆积如山却找不到营销突破... 国内服务器 3个月前440
大数据新视界 — Hive 数据仓库:架构深度剖析与核心组件详解(上)(1 / 30) 本文聚焦 Hive 数据仓库,开篇回顾 Impala 成果后深入阐述 Hive 起源发展、与传统数据库差异,深度剖析其架构核心组件(元数据存储与运行时引擎)及多种数据存储格式(Parquet、ORC... 国内服务器 3个月前440
计算机毕业设计hadoop+spark+hive音乐推荐系统 大数据毕业设计(源码+LW文档+PPT+讲解) 本文介绍了基于Hadoop+Spark+Hive技术栈的音乐推荐系统设计与实现。系统采用分层架构,包含数据采集、存储、计算、推荐引擎与可视化五大模块,运用协同过滤、深度学习等混合算法实现个性化推荐。通... 国内服务器 3个月前440
Java 大视界5230 台物联网设备时序数据难题破解JavaRedisHBaseKafka 实战全 本文深入探讨了如何利用 Java 生态系统中的关键技术栈(Redis、HBase、Kafka)解决大规模物联网设备时序数据的存储、处理和查询难题。通过一个实际案例,展示了 5230 台设备每秒产生海量... 国内服务器 4个月前440
气象数据分析与可视化系统:基于Spark的大数据处理方案(中科院计算机研究生) 本文介绍了一个基于Spark和Python的气象数据分析项目,专注于高效处理大规模气象数据并生成可视化图表。项目采用双版本实现(Spark+Pandas),严格遵循气象观测标准计算日平均气温,处理57... 国内服务器 4个月前440
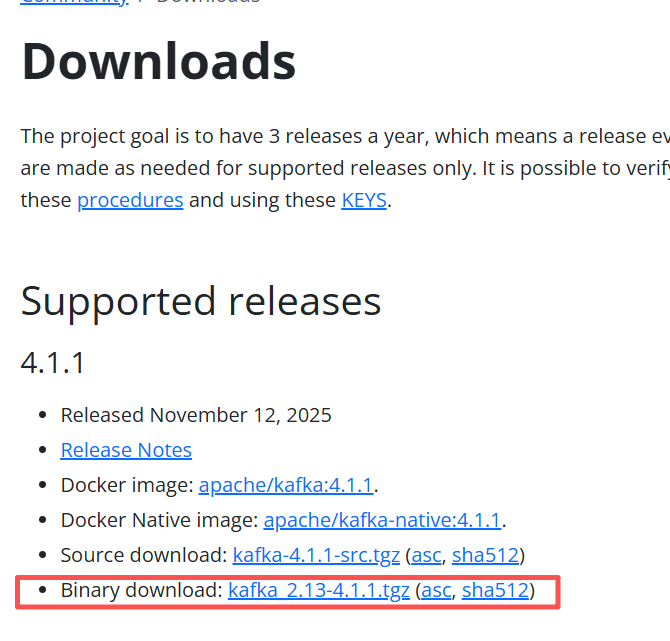
Kafka部署指南:单机开发模式与集群生产模式( 4.1.1 版本) 单机开发模式:适合功能验证和开发测试,配置简单,资源需求低集群生产模式:提供高可用性和容错能力,适合线上业务使用Kafka 4.1.1 完全移除对 ZooKeeper 的依赖,简化了架构部署,同时保持... 国内服务器 4个月前440
Kafka 高可用部署:集群搭建 + 消息可靠性保障 作为一名深耕 Java 后端八年的老兵,我见过太多因 Kafka 部署不当导致的线上故障:单节点宕机引发消息积压、副本配置不合理导致数据丢失、生产者 acks 参数错误造成消息重复……Kafka 作为... 国内服务器 4个月前440