RabbitMQ – 分布式追踪:集成 SkyWalking 实现消息链路追踪 Bean@Bean@Bean统一 Agent 版本:确保所有服务使用相同版本的 SkyWalking Agent。合理命名服务应具有业务含义(如生产环境使用持久化存储:避免 H2 导致数据丢失。监控 ... 国内服务器 2个月前230
从 Kafka 告警到前端实时可见:SSE 在故障诊断平台中的一次完整落地实践 ♥️作者:小宋1021🤵♂️个人主页:小宋1021主页♥️坚持分析平时学习到的项目以及学习到的知识,和大家一起努力呀!!!🎈🎈加油!加油!加油!加油【写在前面】这篇文章的目标不是再讲一遍“什么是 S... 国内服务器 2个月前260
数据仓库核心概念:事实表和维度表详解与实战应用 事实表是数据仓库中存储业务度量值、量化指标、可统计数据的核心表,是数仓的主体数据。事实表 = 业务发生的客观事实 + 可统计的数字指标,记录的是企业的业务行为结果。数字、指标、度量、行为记录维度表是数... 国内服务器 2个月前250
【赫兹威客】完全分布式Spark测试教程 本文档详细介绍了完全分布式Spark集群(3台虚拟机)的独立测试流程。测试前需确保Hadoop、ZooKeeper服务已启动,使用hertz账号登录。测试步骤包括:1)检查虚拟机状态;2)建立SSH连... 国内服务器 2个月前260
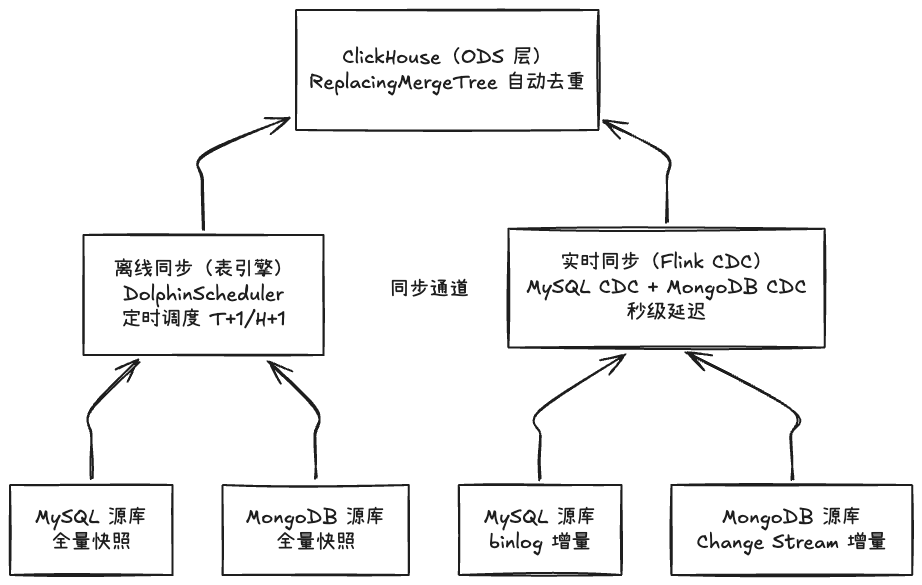
ClickHouse + Flink + DolphinScheduler:中小厂三件套搞定离线+实时数仓,告别 Hadoop 全家桶 本文介绍了一种轻量级离线+实时数仓解决方案,仅需ClickHouse、DolphinScheduler和Flink CDC三个组件。针对中小团队需求,该方案避免复杂Hadoop生态,实现高效低成本数仓... 国内服务器 2个月前460
大数据领域Doris的内存管理与优化策略 在大数据时代,数据量呈爆炸式增长,对数据处理和分析的效率提出了更高的要求。Doris作为一款高性能的MPP(大规模并行处理)分析型数据库,在处理海量数据时发挥着重要作用。而内存管理是Doris性能的关... 国内服务器 2个月前210
计算机毕业设计hadoop+spark+hive游戏推荐系统 游戏可视化 大数据毕业设计(源码+文档+PPT+讲解) 本文介绍了基于Hadoop+Spark+Hive的游戏推荐系统设计方案。系统采用分布式架构处理TB级用户行为数据,通过Hive构建数据仓库,实现用户画像和游戏标签管理。核心技术包括两种推荐算法:基于用... 国内服务器 2个月前260
Spark企业级应用案例:电商用户行为分析实战 某电商平台日均产生5TB用户行为数据批处理慢:用Hive分析全量数据需4小时,无法支撑“上午出报表、下午做运营”的需求;实时性差:用Flink做流处理但批处理能力弱,无法统一批流逻辑,维护成本高;无法... 国内服务器 2个月前250
计算机毕业设计PySpark+Hadoop+Hive+LSTM模型美团大众点评分析+评分预测 美食推荐系统(源码+论文+PPT+讲解视频) 本文介绍了一个基于PySpark+Hadoop+Hive+LSTM的美团大众点评数据分析与评分预测系统。研究通过融合大数据技术与深度学习模型,旨在解决传统评分预测方法在数据利用、模型扩展性和冷启动问题... 国内服务器 2个月前400
学会大数据分布式存储,迈向技术新高度 学会分布式存储,不是"多学一个技术"——它是你理解大数据、云计算、AI的"钥匙"。当你能搭建一个分布式存储集群,能调优它的性能,能解决它的故障时,你已经从&qu... 国内服务器 2个月前230