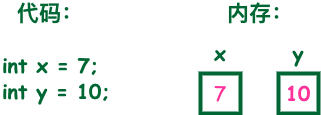Kafka – 环境搭建保姆级教程(Windows/Linux/Mac通用) Kafka环境搭建指南 本文提供一份详细的Kafka环境搭建教程,适用于Windows、Linux和macOS系统。主要内容包括: 准备工作:确认系统支持情况,安装Java环境(推荐JDK 11/17... 国内服务器 2个月前420
基于Hadoop的新能源汽车充电站管理系统的设计与实现99225-计算机毕设原创(免费领源码+带部署教程) 本文设计并实现了一种基于Hadoop的新能源汽车充电站管理系统。该系统采用B/S架构,利用Hadoop框架处理海量充电数据,包括充电记录、财务信息等,实现高效存储与分析。系统分为车辆用户和管理员两大模... 国内服务器 3个月前420
6、Spark 函数_u/v/w/x/y/z Spark SQL函数摘要: ucase/upper:将字符串转为大写(1.0.1+) unbase64/unhex:Base64/十六进制转二进制(1.5.0+) uniform:生成指定范围的随机... 国内服务器 3个月前420
Java语言提供了八种基本类型fdz 变量就是申请内存来存储值。也就是说,当创建变量的时候,需要在内存中申请空间。内存管理系统根据变量的类型为变量分配存储空间,分配的空间只能用来储存该类型数据。因此,通过定义不同类型的变量,可以在内存中储... 国内服务器 3个月前420
【Bayesian Analysis 2023】大数据背景下的分布式贝叶斯模型选择 摘要 本文针对海量数据集的分布式贝叶斯模型选择问题,提出了一种基于边际似然的创新方法。传统"分而治之"策略中的投票机制存在统计功效不足的问题,而新方法通过引入&am... 国内服务器 3个月前420
大数据领域数据工程的存储性能优化 随着电商、物联网、AI等领域的爆发,企业每天产生的用户行为日志、传感器数据、模型训练样本等已达PB级。传统存储方式(如关系型数据库)在面对“数据海”时,常出现“存不下、查得慢”的问题。本文聚焦大数据存... 国内服务器 3个月前420
Spring Kafka消费者被踢出组?CommitFailedException异常全面解析与解决方案 摘要 本文深入分析了Spring Kafka中常见的CommitFailedException异常,揭示其根源在于消费者被踢出组导致偏移量提交失败。问题通常由消息处理耗时过长或心跳超时触发,Sprin... 国内服务器 3个月前420
放弃Canal后,我们用Flink CDC实现了99.99%的数据一致性 对数据的实时性要求越来越高。传统的离线数仓(T+1)已无法满足业务对秒级响应的需求,而实时数仓和数据湖(Data Lake)架构正成为主流。然而,如何将业务数据库中的变更数据(Insert/Updat... 国内服务器 3个月前420
HBase与DynamoDB对比:云数据库选择 在云计算和大数据时代,分布式数据库成为处理海量结构化/半结构化数据的核心基础设施。HBase作为Apache开源项目,基于Hadoop生态构建,提供高吞吐、可扩展的列式存储;DynamoDB是AWS推... 国内服务器 4个月前420