Java 大视界 —— Java 大数据在智能农业病虫害精准识别与绿色防控中的创新应用 Java大数据赋能智能农业病虫害精准识别与绿色防控 本文探讨了Java大数据技术在智能农业病虫害防治中的创新应用。传统农业依赖人工巡检和经验判断,存在误判率高(达45%)、预警滞后和农药滥用等问题。而... 国内服务器 5个月前420
【大数据基础】大数据处理架构Hadoop:03 Hadoop的安装与使用 本文讲解在Ubuntu Kylin 16.04 LTS下Hadoop安装配置流程,涵盖安装系统与软件、创建用户、配置SSH、安装Java,以及单机和伪分布式安装与测试等关键步骤。 国内服务器 5个月前420
AI提效指南:生成精美PPT与漫画 用 NotebookLM 导入资料,在 Studio 生成 Slide Deck 并导出 PDF,再转换为 PPT;并用文本+提示词模板在信息图生成 2x2 四格漫画,用于更直观讲解知识点。 国内服务器 5个月前420
【计算机毕设选题推荐】基于Spark+Django的旅游保险大数据可视化分析系统源码 毕业设计 选题推荐 毕设选题 数据分析 机器学习 数据挖掘 本项目基于Spark+Django构建了一个旅游保险数据可视化分析系统。系统利用Spark对海量保险数据进行高效处理与分析,涵盖销售、客户、出行及风险等多个维度。分析结果通过Django后端接口,以E... 国内服务器 5个月前420
Java 大视界 — Java 大数据机器学习模型在电商供应链库存协同管理与成本控制中的应用(421) 本文结合华北鲜达(生鲜)、智选 3C(3C)两个实战案例,详解 Java 大数据 + 机器学习(LSTM/GNN)在电商供应链库存协同与成本控制的应用。涵盖需求预测(含生鲜保质期约束)、库存分配(含冷... 国内服务器 5个月前420
大数据领域 Hadoop 与 NoSQL 数据库的协同应用 随着互联网、物联网的发展,企业每天产生的日志、用户行为、设备数据等呈指数级增长(据IDC预测,2025年全球数据量将达175ZB)。存储能力有限:无法弹性扩展存储TB级甚至PB级数据;计算效率低:复杂... 国内服务器 5个月前420
Java 大视界 — Java 大数据在智能家居能源消耗趋势预测与节能策略优化中的应用(433) 本文探讨了Java大数据技术在智能家居能源管理中的应用。针对当前智能家居存在的"数据孤岛、预测缺失、策略僵化"三大痛点,提出了一套基于Java生态的能源消耗预测与优... 国内服务器 5个月前420
踩过坑才明白:为什么 ZooKeeper 集群才是正经事 本文详细介绍了ZooKeeper集群的搭建过程。首先通过三台虚拟机配置主机名、关闭防火墙、设置IP地址等环境准备工作。接着在三台机器上安装ZooKeeper,配置zoo.cfg文件并创建数据目录。重点... 国内服务器 2个月前410
计算机毕业设计hadoop+spark农作物产量预测分析 农作物爬虫 农产品可视化 农产品推荐系统 机器学习 深度学习 大数据毕业设计(源码+LW文档+PPT+详细讲解) 本文介绍了一个基于Hadoop+Spark的农作物产量预测分析系统研究项目。该项目旨在利用大数据技术解决传统农业预测方法在数据规模、计算效率和特征提取方面的局限。研究内容包括多源数据整合、分布式特征工... 国内服务器 3个月前410
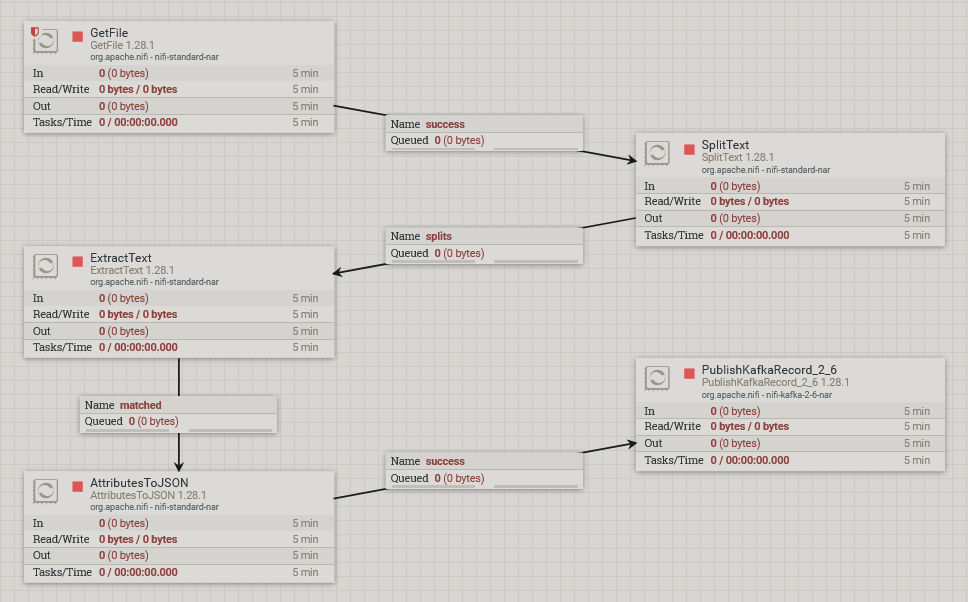
NIFI【应用 02】1.28.1版本使用实例分享(GetFile、SplitText、ExtractText、PublishKafkaRecord_2_6)配置使用及模板分享(txt文件解析) NIFI 1.28.1版本使用实例分享(GetFile、SplitText、ExtractText、PublishKafkaRecord_2_6)配置使用及模板分享(txt文件解析) 国内服务器 3个月前410