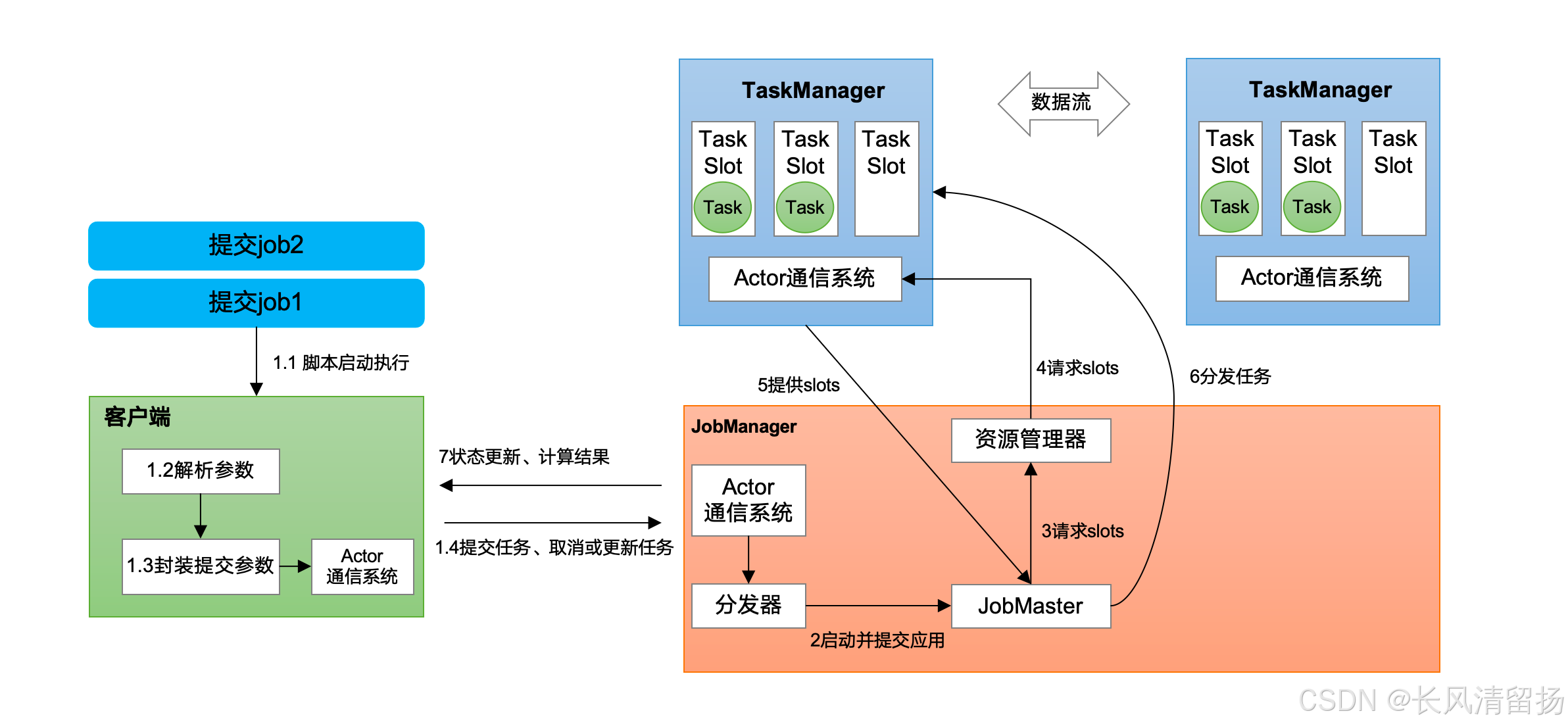
Flink 快速入门 本文详细介绍了Apache Flink的系统架构和核心概念,适合深入学习和理解Flink的开发者。文章以Standalone会话模式为例,详细解析了Flink的作业提交和执行流程,包括客户端、JobM... 国内服务器 4个月前410
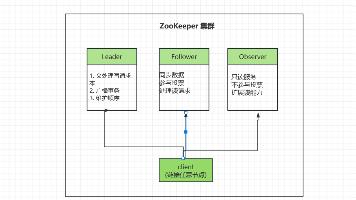
ZAB 协议深度解析:ZooKeeper 分布式一致性的核心 ZooKeeper核心共识协议ZAB(ZooKeeper Atomic Broadcast)详解 摘要: ZAB协议是Apache ZooKeeper实现强一致性的核心机制,通过两种工作模式保证数据安... 国内服务器 4个月前410
基于NoSQL数据库的大数据诊断性分析方案 你是否遇到过这样的场景?用MongoDB存储的电商订单系统,突然查询延迟从50ms飙升到500ms,日志里却只有“slow query”警告;Cassandra集群的写吞吐量骤降,监控面板显示“pen... 国内服务器 4个月前410
深度剖析:如何通过数据即服务释放大数据商业价值? 你是否遇到过这样的场景?某零售企业积累了10年的用户消费数据,却因“数据锁在各个系统里”“分析需要找IT部门排队”“结果总对不上业务需求”,最终这些数据成了“电子垃圾”。类似的问题在金融、制造、医疗等... 国内服务器 4个月前410
大数据数据服务架构设计:核心要点与最佳实践 在当今数字化时代,大数据已经成为企业和组织的重要资产。大数据数据服务架构设计的目的在于构建一个高效、稳定、可扩展的架构,以支持对海量数据的存储、处理、分析和共享。本文章的范围涵盖了大数据数据服务架构设... 国内服务器 4个月前410
深入Spark核心:Shuffle全剖析与实战指南 在 Spark 的分布式计算体系里,Shuffle 被定义为数据重新分布的关键过程。当我们执行那些需要跨分区聚合数据的操作时,Shuffle 便会被触发。其核心任务是将上游 Stage 的输出数据,按... 国内服务器 4个月前410
【大数据分析毕设选题】基于Hadoop+Django天猫订单交易系统全解析 毕业设计 选题推荐 毕设选题 数据分析 机器学习 数据挖掘 这是一个基于Hadoop和Django的毕设项目,主要对天猫订单数据进行可视化分析。后端用Spark处理海量数据,前端用Echarts画出销售趋势、地域分布等图表,帮你把复杂的数据看得明明白白。 国内服务器 4个月前410
【大数据选题指导】数据科学与大数据专业毕设选题大全:300 个热门课题推荐 数据科学与大数据专业的毕业设计选题方向,包括数据采集与预处理、大数据存储与管理、大数据处理与分析、大数据可视化、大数据应用开发、大数据安全与隐私保护等核心领域。适合计算机科学与技术、软件工程、数据科学... 国内服务器 4个月前410
大数据领域实用BI工具的使用心得分享 当你面对TB级别的销售数据、用户行为日志或供应链台账时,是否曾像面对一本“乱码书”一样无从下手?BI(商业智能)工具就是大数据时代的“数据翻译官”——它能将晦涩的原始数据转化为直观的图表、可交互的 d... 国内服务器 4个月前410
CMake报错symbol lookup error?手把手教你修复archive_write_add_filter_zstd缺失问题 本文详细解析了CMake构建过程中遇到的`symbol lookup error: undefined symbol: archive_write_add_filter_zstd`报错问题,提供了从基... 国内服务器 4个月前410