Java 大视界 — 基于 Java 的大数据实时流处理在智能电网分布式电源接入与电力系统稳定性维护中的应用 Java大数据实时流处理助力智能电网稳定性提升 摘要:针对分布式电源接入导致的电网稳定性问题,本文提出基于Java生态的实时流处理解决方案。通过Kafka实现高并发数据采集(10万条/秒),Flink... 国内服务器 6个月前950
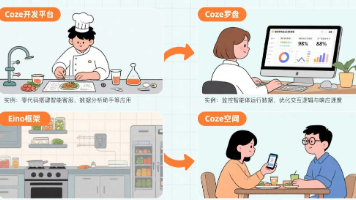
【Coze-AI智能体开发】【一】初识Coze:零代码玩转 AI 智能体开发,新手也能轻松搭建专属 AI 应用! 字节跳动推出的Coze(扣子)AI智能体开发平台,通过零代码/低代码方式降低了AI应用开发门槛,让非技术用户也能快速构建基于大模型的各类AI应用。平台提供可视化组件、插件集成、知识库管理等功能,支持智... 国内服务器 6个月前950
Spark 核心角色深度剖析:Driver, Executor, Master, Worker 全解析 Spark 的世界就像一场大型协作演出:Driver 负责指挥全局,Cluster Manager 分配资源,Worker 和 Executor 则在后台默默干活。每个 RDD 分区都化身为并行 Ta... 国内服务器 6个月前950
【消息队列】kafka2.0.0安装(单机)及基本命令 本文详细介绍了在Linux系统上安装配置JDK和Kafka的完整流程。主要内容包括:1)JDK环境安装与配置;2)Kafka单机部署,包含Zookeeper配置、Broker参数调整及SASL认证设置... 国内服务器 6个月前950
Tkinter Text 文本框组件完全指南 核心定位:Text 是 Tkinter 多行文本核心组件,支持显示 / 编辑 / 格式化,功能远超 Entry;基础操作:重点掌握 insert()/get()/delete() 实现文本增删查,通过... 国内服务器 6个月前930
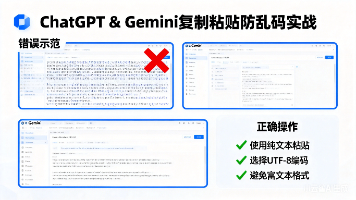
ChatGPT和Gemini复制粘贴如何不乱码 AI的进步,不该被“复制粘贴”这种基础操作拖后腿。我们期待的,不是更聪明的模型,而是更顺滑的人机协作体验。当ChatGPT写出一段完美的算法说明,当Gemini为你整理好一份技术调研,我们想做的,是立... 国内服务器 6个月前930
DooTask资产管理插件全面焕新:全流程数字化赋能企业资产精细管控 DooTask资产管理插件完成重大升级,实现资产全生命周期数字化管理。新版本覆盖预算编制到报废处置全流程,支持移动端操作与自动提醒,提供多种盘点方式确保账实相符。智能化分类查询和精细化权限管理提升效率... 国内服务器 6个月前930
HBase数据库:分布式列式存储的王者之路 摘要:HBase数据库的分布式列式存储解析 HBase作为Apache Hadoop生态中的分布式列式数据库,以其卓越的海量数据处理能力解决了传统关系型数据库的扩展瓶颈。本文深入剖析了HBase的核心... 国内服务器 4个月前920
基于30年教学沉淀的清华大学AI通识经典:《人工智能的底层逻辑》 《人工智能的底层逻辑》是清华大学张长水教授基于30年教学经验编写的AI通识经典。全书采用12章系统化架构,从基础到前沿完整呈现AI知识体系,独创"四维解析"框架(任... 国内服务器 6个月前920